Python爬虫报错网站签名校验
Python运行下面的程序报错,怎么解决(好像是网站签名校验啥的没通过。)谢谢!


dict_data字典没有content
应该是requests没有获取到正确的内容,可能是请求的data参数不对,或者requests伪造的头部信息不全。
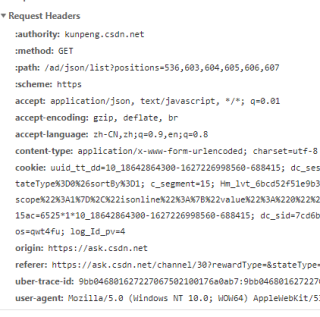
要在headers中添加抓包时的请求头求参数
比如
url = "https://xxxxxxxxxxx"
headers={
'User-Agent': 'xxxxxxxxxxx',
'Host' : 'xxxxxxxxxxx',
'Origin' : 'xxxxxxxxxxxxx',
'Referer' : 'xxxxxxxxxxxxxx',
'Cookie': 'xxxxxxxxxxxxxxxx'
}
res = requests.get(url,headers=headers)
其中请求头的参数 'User-Agent','Host','Origin', 'Referer','Cookie'可以在浏览器的f12控制台的Network中看到


将 get_data_from_url 函数修改一下:
def get_data_from_url(self):
r=pc.post(self.url,headers=self.head,data=self.data,verify=False)
return r.content.decode()
如果真的是签名验证问题,在 post 的参数里添加 verify=False 则可以跳过签名验证。
望采纳。