用java实现高速度处理获取的字符串String
请教 想要做一个抢先执行的工具!用java来实现;实现原理,一端源源不断的接收字符串String数据(网络服务器读取,预计1ms接收一条,每秒钟上千条),然后要求快速的对这些数据筛选和做出反应(由于每一秒接收的数据非常多,且要求对符合要求的数据处理的足够快,所以想要采用一开始固定启动多条线程并行读取和处理这些数据,如果每一条数据都创建一个线程分析这样太消耗资源和影响速度),请问java可以用什么方式来实现呢? 分析过的数据不需要存储
可以用线程池实现灵活的线程分配。
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(…);
或者
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(…);
threadPoolExecutor.execute(…);
如果你是因为字符串处理速度不够快而想用多线程的话,恐怕难以达到你的预期了。多线程无法提高硬件运行速度,只能更多地挖掘硬件和能力而已。
利用线程池的方式就可以实现多线程循环处理接收的任务!
通过OkHTTP转发一下,转发到不同controller中处理数据。
用消息中间件会不会好点
生产者线程推送字符串到消息队列,然后多个消费线程监听处理数据
用消息中间件
这个属于生产者/消费者问题。生产者产生一条数据后,可以:
1、生成一个处理任务,交给消费线程池处理,消费者使用一个线程池;
2、或者将消息放到一个内存队列中,然后启动多个消费者线程,都从这个队列中获取消息并处理;
3、再或者就是将消息放到消息中间件,如kafka、rabbitmq等,然后启动多个消费者程序来处理
首先最好使用池化技术,初始化时给线程池设置一批线程数,这样就不用频繁创建线程消耗系统性能,其次,处理的字符串是否入库,如果是,尽量也使用多线程批量处理,同时入库的表尽量不要设置太多索引,因为影响读写操作效率
用消息队列,使用RabbitMQ或者Kafka,可靠性要求更高用RabbitMQ,性能要求更高选Kafka。
消息队列是异步的,所以你接收字符串和处理字符串可以分开,然后按你选的消息队列模型去处理接收到的字符串就可以了。
可以像下图这样创建一个线程池。
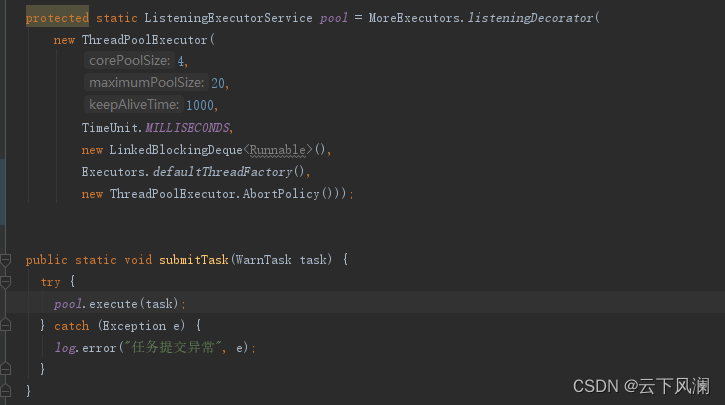
如果一直高速处理,没有波峰波谷的话,可以把核心线程数设置的大一些(一般是你的电脑内核数+1,具体还得看压测情况),并且核心线程数可以等于最大线程数,这样就省去了线程创建和销毁的开销。
图中等待队列用的是LinkedBlockingDeque(阻塞队列,并且没有设置最大值),看你的需求,如果要是考虑有耗时操作,并且内存可能会溢出的话,可以设置队列最大值,如果所有的线程都在运行任务,阻塞队列也满了(设置了最大值的情况下),就会走拒绝策略,也就是图中的new ThreadPoolExecutor.AbortPolicy(),AbortPolicy是指的丢弃任务。
按照你的需求设置拒绝策略。
- ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。 默认策略
- ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
- ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
我都不知道你具体要做啥,我们也只能给你那些通用的回答说法:
负载均衡,线程池,如果处理字符串重复率高还可以缓存,更换硬件,修改代码提高效率
接收数据,采用线程池技术,多线程接受处理数据;
如果涉及到对数据进行线程安全地简单计算,可以使用LongAdder或者LongAccumulator进行处理单台处理;
分布式部署的话,可以引入分布式存储,一般采用Redis存储。
1.如果是单纯就用Java不考虑中间件,就是Netty接收,多线程+线程池处理接收后的数据。
2.考虑使用中间件,使用消息队列,追求吞吐量就Kafka,或者RocketMQ。中间件的部署使用集群方式,提高硬件配置
分三步吧
1、配置需要过滤的词字典
2、对接收的字符串采用分词算法
3、然后再消费匹配的字符串
其中1、2可以参考ElasticSearch的analysis-ik分词器实现,第三点的话跟业务有关了,
我们主要的是优化1,2点,可以用C语言把analysis-ik实现提供给JAVA调用,主要从内存的节省跟操作效率去考虑。
推荐你使用消息队列处理,消息队列可以支持多台服务器同时处理你得数据
参考多线程下载,只能用这个,其它容易混淆
第一种:这种的话数据处理可以使用异步请求多线程来解决问题;每一个字符串给一个时间戳,使用redis的锁的方式来解决多次处理的问题。
1,接收数据后,给一个时间戳,使用异步请求其他接口来处理数据
2,异步处理接口,调用与不处理方法来处理;结果保存或者其他处理皆可。
我们之前的c端风险控制管理就是这样做的;
第二种:上述方法无法满足的情况下可以考虑集群+异步,速度更快
队列或者消息中间件的话一般是保证结果正确;根据你的需求来设置需要的方案就好。
1.kafka,flink也是java写的啊
2.没必要自己处理,数据肯定要处理的,处理玩的要落地,架构选好符合业务就行,又不是行业大拿,也是不大公司哪有那多成本,直接借鉴人家的架构,自己改改就行了
3.感觉你搞错,这东西没必要自己开发,你想的大公司都做好了,也开源了,拿来用就行
1、indexof(String s)
s为要搜索的字符串,如果查找到了就返回第一个匹配到的索引位置,如果没有匹配到就返回-1
String str = "ljavadfjsdfhgjjfsjavajfdsj";
System.out.println(str.indexOf("java"));
2、indexof(String s,int n)
s为要搜索的字符串,n为开始索引的位置,如果没有匹配到就返回-1
3、lastIndexof(String s)
返回最后一个指定字符串匹配到的位置,没有就返回-1
4、startWith(String s)
判断字符串是否以指定的字符串开头,返回类型为boolean类型
5、endsWith(String s)
判断字符串是否以指定的字符串结尾,返回类型为boolean类型
6、trim()
用于删除字符串首尾的空格
7、split(String s)
根据指定字符串分割原字符串,结果返回一个数组
8、subString(int n)
用于分割字符串,结果返回一个新的字符串,此字符串可与indexof配合分割字符串
9、contains(String s)
查找字符串中是否包含s,结果返回boolean类型
String str = "ljavadfjsdfhgjjfsjavajfdsj";
System.out.println(str.indexOf("java"));//1
System.out.println(str.indexOf("java", 10));//17
System.out.println(str.lastIndexOf("java"));
System.out.println(str.startsWith("java"));//false
System.out.println(str.endsWith("java"));//false
System.out.println(" Hello world ".trim());
String ss = "java,php,c,pyhon,html";
String[] s1 = ss.split(",");
for (String s : s1) {
System.out.println(s);
}
//截取第一个java开始到最后一个java之前的字符串
String s2 = str.substring(str.indexOf("java"), str.lastIndexOf("java"));
System.out.println(s2);
朋友我提几点建议
1、相关的表一定要按相关条件建立索引。
2、尽是用SQL语句,比你一条一条的做要快很多!!
3、如果数据库太大了,定期清理数据并做压缩修复。
望采纳谢谢啦