python爬虫IndexError
问题遇到的现象和发生背景
第一行起始行是17 , 也就是从导入包开始为第一行
问题相关代码,请勿粘贴截图
import urllib.request
from lxml import etree
def create_request(page):
if (page == 1):
url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/qinglvtupian_' + str(page) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36 Edg/103.0.1264.37'
}
request = urllib.request.Request(url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content):
tree = etree.HTML(content)
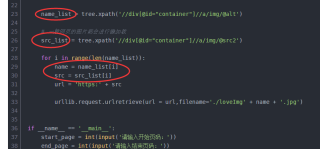
name_list = tree.xpath('//div[@id="container"]//a/img/@alt')
# 一般网页的图片都会进行懒加载
src_list = tree.xpath('//div[@id="container"]//a/img/@src2')
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:' + src
urllib.request.urlretrieve(url = url,filename='./loveImg' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input('请输入开始页码:'))
end_page = int(input('请输入结束页码:'))
for page in range(start_page,end_page+1):
# (1)请求对象定制
request = create_request(page)
# (2)获取网页源码
content = get_content(request)
# (3)下载图片
down_load(content)
运行结果及报错内容
请输入开始页码:1
请输入结束页码:5
Traceback (most recent call last):
File "D:/big data/python/workpython/072_解析_站长素材.py", line 62, in <module>
down_load(content)
File "D:/big data/python/workpython/072_解析_站长素材.py", line 46, in down_load
src = src_list[i]
IndexError: list index out of range
Process finished with exit code 1
我的解答思路和尝试过的方法
我想要达到的结果
你这两个列表中的元素长度不一样,然后循环的时候超出src_list的值了