Python怎么实现拆分表格中的数据
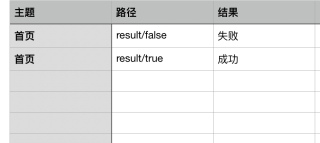
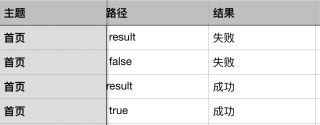
怎么将前面这张表的数据通过/拆分为下面这张表的数据。用到的包xlrd和xlwt
import xlrd
import xlwt
def readFromExcelByXlrd(filename, toSaveFilename, sheetName='Sheet1'):
try:
book1 = xlrd.open_workbook(filename)
sheet1 = book1.sheet_by_name(sheetName)
nrows = sheet1.nrows
# ncols = sheet1.ncols
book2 = xlwt.Workbook(encoding='utf-8')
sheet2 = book2.add_sheet(sheetName, True)
r = 0
for i in range(nrows):
row = sheet1.row_values(i)
params = row[1].split("/")
for time in range(len(params)):
sheet2.write(r, 0, row[0])
sheet2.write(r, 1, params[time])
sheet2.write(r, 2, row[2])
r += 1
book2.save(toSaveFilename)
except Exception as e:
print(str(e))
if __name__ == '__main__':
filename = r'C:\Users\Lenovo\Desktop\1.xlsx'
filename1 = r'C:\Users\Lenovo\Desktop\2.xlsx'
readFromExcelByXlrd(filename, filename1)
这不就是字符串分割?按行读取,split('/')分割第1列数据,然后第0列和第2列不变,分割多少份就生成多少行数据,分割完了再写入新文件