python爬虫html获取不全
最近发现了一个网站,想用python爬虫爬取其中的图片
https://www.aigei.com/view/70774.html?page=1
首先使用requests库试了一下
import requests
import re
url = r"https://www.aigei.com/view/70774.html?page=2"
print(url)
headers = (太长了,这里就不放了,其中有user-agent , cookie)
html = requests.get(url, headers=headers).content.decode("utf-8")
print(html)
但是发现没有想要的内容
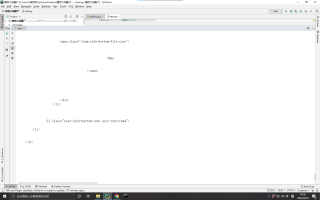
出现了很多的空行, 用selenium试了一下, 依然不行
from selenium import webdriver
import re
browser = webdriver.Chrome()
browser.get(r"https://www.aigei.com/view/70774.html?page=2")
html = browser.page_source
print(html)
browser.quit()
本人是初学者,希望各位达人帮忙解决
其实有的,但是这个网站应该是为了懒加载把url用base64密了一下,然后再动态加载, 其实我下面发的这个就是url 是base64后的url 解码后就是
https://s1.aigei.com/src/img/png/4a/4a6de48586f54845b67f8d3d874dacf5.png?imageMogr2/auto-orient/thumbnail/!116x115r/gravity/Center/crop/116x115/quality/85/&e=1735488000&token=P7S2Xpzfz11vAkASLTkfHN7Fw-oOZBecqeJaxypL:Po14r-y2O1ya-md6RQhO1iuxTxQ=
原文
src='//cdn-sqn.aigei.com/assets/site/img/icon/grey.gif' data-original='aHR0cHM6Ly9zMS5haWdlaS5jb20vc3JjL2ltZy9wbmcvNGEvNGE2ZGU0ODU4NmY1NDg0NWI2N2Y4
ZDNkODc0ZGFjZjUucG5nP2ltYWdlTW9ncjIvYXV0by1vcmllbnQvdGh1bWJuYWlsLyExMTZ4MTE1
ci9ncmF2aXR5L0NlbnRlci9jcm9wLzExNngxMTUvcXVhbGl0eS84NS8mZT0xNzM1NDg4MDAwJnRv
a2VuPVA3UzJYcHpmejExdkFrQVNMVGtmSE43Rnctb09aQmVjcWVKYXh5cEw6UG8xNHIteTJPMXlh
LW1kNlJRaE8xaXV4VHhRPQ==' data-is-original-base64='true'