挑战求素数函数的速度!
自定义一个求素数的函数: prime(n) = 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, ..... ,其中 n = 1,2,3,4,5,6,7,8,9,10......
时间限制:第10万项在9秒以内,第1万项在0.3秒以内(计时硬件:Pentium(R)Dual-Core E5400 + 4GB Ram)
>>> import time
>>> t=time.time();prime(100000);time.time()-t
1299709
8.907615661621094
>>> t=time.time();prime(10000);time.time()-t
104729
0.296400785446167
>>> [prime(i+1) for i in range(10)]
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29]
import time
import numpy as np
def find_prime(top):
"""找出小于top的所有质数"""
prime_list = list() # 空数组,用于存放找到的质素
mid = int(np.sqrt(top)) # 判断100是否是质数,只需要分别用2,3...等质素去除100,看能否被整除,最多做到100的平方根就够了
nums = np.arange(top) # 生成0到上限的数组,数组元素的值等于其索引号,相对于python的[0,1,2,3,...]
nums[1] = 0 # 数组第1和元素置0,从2开始,都是非0的
while True: # 循环
primes = nums[nums>0] # 找出所有非0的元素
if primes.any(): # 如果能找到
p = primes[0] # 则第一个元素为质数
prime_list.append(p) # 保存第一个元素到返回的数组
nums[p::p] = 0 # 这个质数的所有倍数,都置为0(表示非质素)
if p > mid: # 如果找到的质数大于上限的平方根
break # 则退出循环
else:
break # 全部0,也退出循环
prime_list.extend(nums[nums>0].tolist()) # nums里面剩余的非0元素,都是质数,合并到返回的数组中
return prime_list # 返回结果
if __name__ == '__main__':
for top in (10_000, 100_000, 1_000_000, 10_000_000):
t0 = time.time()
prime_list = find_prime(top)
t1 = time.time()
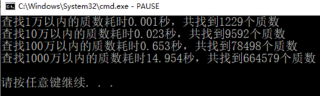
print('查找%d万以内的质数耗时%0.3f秒,共找到%d个质数'%(top//10000, t1-t0, len(prime_list)))
运行结果:
查找1万以内的质数耗时0.001秒,共找到1229个质数
查找10万以内的质数耗时0.023秒,共找到9592个质数
查找100万以内的质数耗时0.653秒,共找到78498个质数
查找1000万以内的质数耗时14.954秒,共找到664579个质数
import time
def prime(n):
a = [2]
b = a[-1]+1
while len(a)!=n:
for i in range(len(a)):
if b%a[i] == 0:
break
if a[i]**2 >b:
a.append(b)
break
b+=1
return a[-1]
t = time.time()
c = prime(10000)
print(c)
t = time.time()-t
print(t)
t = time.time()
c = prime(100000)
print(c)
t = time.time()-t
print(t)
难点在于不清楚第10万项大致在什么量级, 如果已知这个数不大于N, 可以在[2, N)内用欧拉筛, 这应该是比较快的筛选素数的方法了.