xpath用for循环为什么只拿到一条数据?
我想知道为什么我这个只能抓一条数据
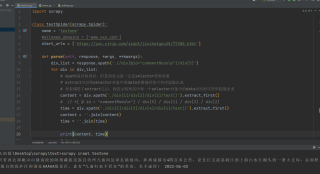
mport scrapy
class textSpider(scrapy.Spider):
name = 'textone'
#allowed_domains = ['www.ctrp.com']
start_urls = ['https://you.ctrip.com/sight/jiuzhaigou25/77380.html']
def parse(self, response, *args, **kwargs):
div_list = response.xpath('.//div[@id="commentModule"]/div[5]')
for div in div_list:
# xpath返回的列表,但是列表元素一定是selector类型对象
# extract可以将selector对象中的data参数储存的字符串提取出来
# 列表调用了extract之后,则表示将列表中每一个selector对象中的data对应的字符串提取出来
content = div.xpath('./div[1]/div[2]/div[2]/text()').extract_first()
# // *[ @ id = "commentModule"] / div[5] / div[1] / div[2] / div[2]
time = div.xpath('./div[1]/div[2]/div[4]/div[1]/text()').extract_first()
content = ''.join(content)
time = ''.join(time)
print(content, time)
打断点调试就明白了