python爬虫返回的html文件打开网页是空的
今天第一次学习爬虫 遇到了这个问题
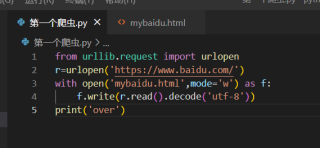
生成了这个html文件 但是我看视频课演示都是一大串东西 我的只有这几行
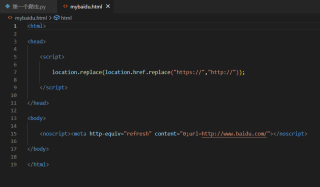
然后运行html文件 网页是空白的
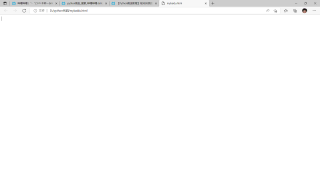
想问一下是什么原因
很正常,一个网页能运行,不但需要html文件,还需要css和js文件在背后支撑。(前端和后端)
你只是爬下来了一个html文件,自然什么都不会展示出来。
你仔细想想,如果这么轻易的就能被你爬到百度的html文件,并且还能跟百度一个样子,百度的程序员还活不活了?
今天第一次学习爬虫 遇到了这个问题
很正常,一个网页能运行,不但需要html文件,还需要css和js文件在背后支撑。(前端和后端)
你只是爬下来了一个html文件,自然什么都不会展示出来。
你仔细想想,如果这么轻易的就能被你爬到百度的html文件,并且还能跟百度一个样子,百度的程序员还活不活了?