Java1.8中HashMap扩容的特殊情况?
Java1.8中HashMap如果put键值对时,key的hashcode一样但内容不一样,就会一直在数组同一个位置插入(链表或者红黑树),那么一直插入到扩容门限,进行扩容,Java1.8的扩容机制并没有重新计算hash值,也就是说扩容后那个很长链表或者红黑树还是没有分开,还是很长,那这种情况下的扩容有什么意义?比如说原容量是16,那需要到12个后进行扩容,那如果有13个hash值是xxx...xx110111,他们本来在table[7],扩容后都在table[23],针所有键值对还是在一起,针对这样的情况hashmap是不是无能为例呢,还是说压根不会出现这么多有重复hash值的key。
首先,重新计算hash值是不现实的,不能每次扩容都要用新的hash值算法,而且也不能保证新的hash算法不会产生碰撞(从设计者角度来说,肯定会优先使用最优的hash算法,所以当最优算法都会产生碰撞,那换个算法显然也解决不了问题)
再则,hash值不同的key,也有可能被放在同一个Node链表下,看一下源码中的寻找数组下标的方法
tab[i = (n - 1) & hash]
假设现在数组长度 n = 2 ,有两个key,key1的hash值是2,key2的hash值是4,那么key1对应的数组下标是(2-1)&2 =0,k
ey2的数组下标(2-1)&4=0,所以这两个key都会放在tab[0]里,现在数组扩容到4,那么key1的下标变成(4-1)&2=1,k
ey2的则是(4-1)&4=1,那么在扩容后key1,key2就分在不同的数组里了。原先的链表/树就会被拆开了。
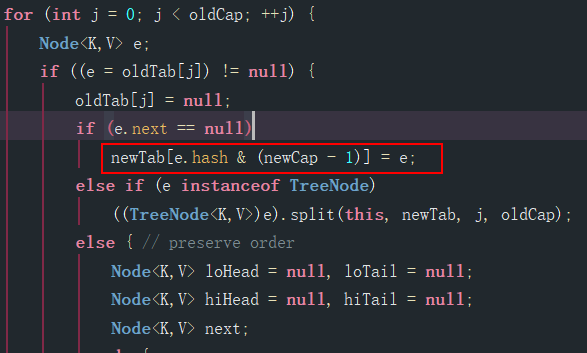
....你看过源码吗?位置有重新计算。
计算hash值是跟你的容量挂钩的,扩容后你原先的数据的角标会发生高低位迁移的过程,并不会出现你说的这种情况