爬取指定类型图片.求解!!
运行这个代码只能爬取关于猫猫类型的图片,只能存在创建好的猫猫文件中。如何做到输入一个指定类型,爬取后保存在指定文件夹中
import requests
import sys
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36 Edg/102.0.1245."
}
def loadImg(index, maxnum=200):
loadnum = 0
while loadnum < maxnum:
url = "https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=0%2C0&"\
"fp=detail&logid=11962624943566928039&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=0&lpn=0&st=-1&word="+index+"&z=0&ic=0&hd=undefined&latest=undefined©right=undefined&s=undefined&se=&tab=0&width=&height=&face=undefined&istype=2&qc=&nc=&fr=&simics=&srctype=&bdtype=0&rpstart=0&rpnum=0&cs=3464307413%2C312436372" \
"&catename=&nojc=undefined&album_id=&album_tab=&cardserver=&tabname=&pn=" + str(loadnum) + "&rn=30&gsm=4&1638875927992="
response = requests.get(url, headers=headers, timeout=3)
# 请求状态
if response.status_code == 200:
print("请求成功!")
##json文件-data-【0-30】-hoverurl
for i in range(30):
ImgUrl = response.json()['data'][i]["hoverURL"]
Img = requests.get(url=ImgUrl, headers=headers)
name = loadnum + i
# 进度显示
print(name)
##二进制保存图片
with open(save_path + index + str(name) + ".jpg", "wb") as f:
f.write(Img.content)
loadnum += 30
# 同类别多索引
label1 = str(input("输入指定的类型:"))
a1 = list(label1)
labels = ["鲨鱼", "猫猫", "小狗", "人像"]
ls = str(labels)
index = {"鲨鱼": ['虎鲨', '鼠鲨', '鲨鱼', '食人鲨', '鲨', '巨鲨'],
"猫猫": ['金渐层', '橘猫', '英短', '波斯猫', '狸花猫'],
"小狗": ['萨摩', '拉布拉多', '柯基', '金毛', '秋田犬'],
"人像": ['合影', '自拍', '明星', '歌手', '美女', ]
}
for lz in label1:
if lz in ls:
#labels = ["鲨鱼", "猫猫", "小狗", "人像"]
'''index = {"鲨鱼": ['虎鲨', '鼠鲨', '鲨鱼', '食人鲨', '鲨', '巨鲨'],
"猫猫": ['金渐层', '橘猫', '英短', '波斯猫', '狸花猫'],
"小狗": ['萨摩', '拉布拉多', '柯基', '金毛', '秋田犬'],
"人像": ['合影', '自拍', '明星', '歌手', '美女', '帅哥']
}'''
need_num = [1000] # 需要的图片数量
print()
else:
print("指定的类型不存在")
sys.exit()
for num in range(1, len(ls)):
# 需要提前创建label文件夹
times = need_num[0] // 200 + 1
save_path = r"C:\Users\God\A\pachong\\" + a1[0] + "\\"
for i in range(times):
loadImg(index[labels[num]][i])
1、为什么只能爬到猫猫类的?
这个跟你输入label1 = str(input("输入指定的类型:"))这句有关,虽然你后边a1 = list(label1)给它定义成列表,但转成列表后就不是你想要的意思,如图:
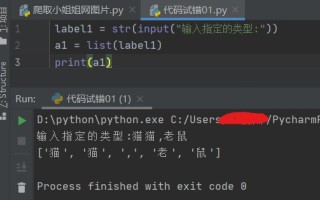
也就是说。不论你输入多少东西,当你后来从列表取得时候,第一个和第二个永远是猫(也就是前400张图片永远是猫),修改的方法就是把你这个index字典嵌套列表删了,要什么搜什么,直接放进url里边
另外,input("输入指定的类型:")本身就是就是字符串类型了,不知道你再给它外边套个str()是要干什么?
2、为什么全都保存在了猫猫的文件夹里?
如第一问所讲,因为你每次列表里的第一个都是“猫”,所以a1 = list(label1)→a1[0]这个文件夹永远是猫(看问题1的图)→就导致save_path = r"C:\Users\God\A\pachong\" + a1[0] + "\"一直在猫这个文件夹
当第一问按照我的思路解决后,第二问自然就不存在了
3、作为一个经常爬图片视频的老色批,我不建议你从百度爬图片,百度出来的图片质量太差,各大壁纸网站它不香?
感觉我说的有道理欢迎联系
思路:输入为索引值,然后从label获取名称传入下载图片函数即可
没太看明白逻辑,是要爬取["鲨鱼", "猫猫", "小狗", "人像"]这四类每类5个分类,然后分别各爬200张放到各自分类目录下吗
关注我,很简单,你把类型作为输入不就行了,然后维护不同的地址