csv文件排序出现问题
问题遇到的现象和发生背景
在爬取数据后要对csv文件进行排序,但通过以下代码排序后发现顺序错误。
问题相关代码,请勿粘贴截图
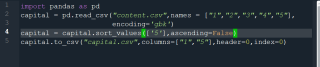
运行结果及报错内容
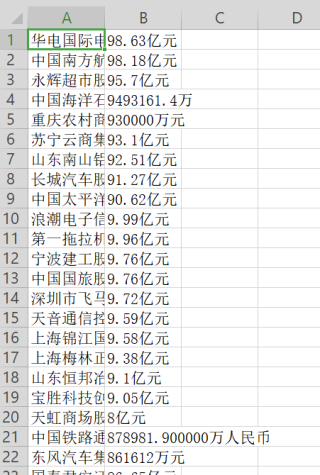
还有爬取出来的文件:
我的解答思路和尝试过的方法
尝试了将单元格改为数值格式但是没有办法保存。
我想要达到的结果
希望能够根据csv文件的第五列进行排序并且去除后面的万和亿。
排序的地方换一下,先转换再排序
import re
def getnum(x):
num1=float(re.findall('(\d+\.?\d+)',x)[0])
num2=10000 if '亿' in x else 1 ##单位万
return num1*num2
capital['amt']=capital['5'].apply(getnum)
capital=capital.sort_values(by='amt',ascending=False)
第5列是字符串类型,并且单位不一致,所以直接排序的结果不正确。要先根据后缀的文字做单位转换,统一单位后转成浮点数,再进行排序。
先去除空行
capital.dropna(how="all")
先把第5列所有的金额转成亿元,去掉汉字,然后再进行排序,试试修改一下代码:
def number(s):
yi = s.find('亿')
wan = s.find('万')
if wan>0:
return float(s[:wan])/10000
elif yi>0:
return float(s[:yi])
capital['5'] = capital['5'].map(number)
capital = capital.sort_values(['5'],ascending=False)
基本思路就是统一单位,去除汉字,排序后再加上统一的单位,看不到全部数据,单位只有亿和万两种单位吗
你可以用Python自带的csv库将数据全部读取出来,改第五列的数据成为数字,然后根据第五列排序,再写入一个新的csv文件就可以了,期间自己想怎么处理就怎么处理
我用的是utf-8编码的csv测试,你可以改成gbk
#-*- coding:utf-8 -*-
import pandas as pd
def get_num(amount:str):
result = 0
index = amount.find(u"亿")
if index > 0:
tmp = amount[0:index]
result = float(tmp) * 1e8
return result
index = amount.find(u"万")
if index > 0:
tmp = amount[0:index]
result = float(tmp) * 1e4
return result
index = amount.find(u"元")
if index > 0:
tmp = amount[0:index]
result = float(tmp)
return result
index = amount.find(u"人")
if index > 0:
tmp = amount[0:index]
result = float(tmp)
return result
return float(amount)
capital = pd.read_csv("test2.csv",names=["1","2","3","4","5"], encoding='utf-8')
print(capital)
for index,row in capital.iterrows():
print(index, row["1"],row["5"])
capital.iat[index,4] = get_num(row["5"])
print("-----------------------")
print(capital)
capital = capital.sort_values(["5"],ascending=False)
print("-----------------------")
print(capital)
capital.to_csv("output.csv", columns=["1","5"], header=0, index=0)
