关于#map#的问题,如何解决?
举一个例子
有一个字典,里面有不同类别的人的映射关系:
map_dic = {
"北京":"beijing",
"上海":"shanghai",
"广州":"guangzhou",
"深圳":"shenzhen"
}
然后我还有一个每个人的出生地信息,只是出生地不是仅包含省名:
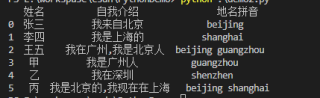
df = pd.DataFrame({
"姓名":["张三","李四","王五","甲","乙","丙"],
"自我介绍" : ["我来自北京","我是上海的","我在广州,我是北京人","我是广州人","我在深圳","我是北京的,我现在在上海"]
})
我希望在df的第三列填入每个人提到的城市拼音,提到两个城市的也相应的填入两个值,
我该怎么做?
import pandas as pd
map_dic = {
"北京":"beijing",
"上海":"shanghai",
"广州":"guangzhou",
"深圳":"shenzhen"
}
df = pd.DataFrame({
"姓名":["张三","李四","王五","甲","乙","丙"],
"自我介绍" : ["我来自北京","我是上海的","我在广州,我是北京人","我是广州人","我在深圳","我是北京的,我现在在上海"]
})
lst = [' '.join([v for k,v in map_dic.items() if k in i]) for i in df.iloc[:,1]]
df.insert(loc=2, column='地名拼音', value=lst)
print(df)
提取df的"自我介绍"一列出来,生成一个list,同时创建一个listnew存放拼音,再用mapdic的每个key去检查是否在这个list中,如果在则将这个key对应的value放在listnew中。最后将这和listnew加入到df中