如何将df的数据进行合并
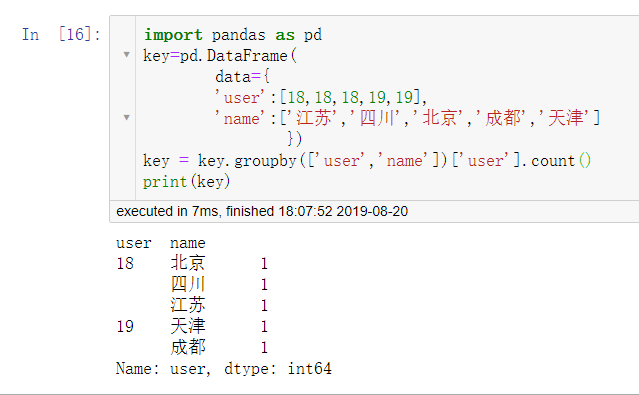
key=DataFrame(
data={
'user':[18,18,18,19,19],
'name':['江苏','四川','北京','成都','天津']
})
我想要将其分类,也是df文件有两列,一列user,一列name
不要使用
key = key.groupby('user')['name'].unique()
输出的效果是
user name
18 '江苏','四川','北京',
19 '成都','天津'
是想达到这种形式吗
key = key.groupby('user')['name'].apply(lambda x:",".join(map(lambda x:"'%s'" % x, x))).reset_index()
你的意思是想找一句函数就能完成的方法吧。。。但是你又不好理解你写的那种方法。你对你理想中的方法有什么描述吗,我觉得这个问题只能用循环处理解决。
你写的方法是把这个循环包装成函数了,楼上的方法也是把unique函数的功能用另外一种手段实现了。