用Python设计如下程序
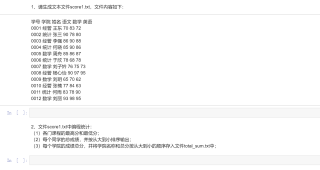
用Python设计上图中的程序,最好涉及数据存储:文件的内容,回答问题采纳后可得到悬赏金额
读取文本的时候如果出现无法解码,可能还要加上encoding='utf-8'
with open('score1.txt','r') as f:
p = f.readlines()
stu = {}
major = {'语文':[],'数学':[],'英语':[]}
college = {}
for i in p[1:]:
s = i.strip().split()
stu[s[2]]=eval(s[3])+eval(s[4])+eval(s[5])
college[s[1]]=college.get(s[1],0)+stu[s[2]]
major['语文'].append(eval(s[3]))
major['数学'].append(eval(s[4]))
major['英语'].append(eval(s[5]))
# (1)各门课程的最高分和最低分:
major['语文'].sort()
major['数学'].sort()
major['英语'].sort()
for i, j in major.items():
print(f'{i}最高分:{j[-1]}\t最低分:{j[0]}')
# (2)每个同学的总成绩,按从大到小排序输出:
for i, j in sorted(stu.items(), key=lambda x:x[1], reverse=True):
print(f'{i}的总成绩:{j}')
# (3)每个学院的成绩总分,按从大到小的顺序存入文件
with open('total_sum.txt','w') as f:
for i, j in sorted(college.items(), key=lambda x:x[1],reverse=True):
f.write(f'{i}学院的总分为{j}\n')
假设是这样的
import pandas as pd
df = pd.DataFrame({'学号':['0001', '0002', '0003', '0004'],
'学院': ['经管', '统计', '经管', '统计'],
'姓名': ['王东', '张三', '李强', '何晓'],
'语文': [70, 90, 86, 85],
'数学': [83, 78, 90, 90],
'英语': [72, 80, 88, 86]})
# 保存为txt
df.to_csv('score1.txt',index=False, header = True, sep='\t')
score1 = pd.read_csv('score1.txt', sep='\t')
score1.head()
# 这个可以看三科的最大最小值
score1.describe()
# 这个可以看总成绩
score1['总成绩'] = score1['语文']+score1['数学']+score1['英语']
score1.sort_values('总成绩', ascending=False)
# 最后一问
total = score1.groupby('学院', as_index=False).sum().sort_values('总成绩', ascending=False)
total_sum = total.drop(columns=['学号','语文','数学','英语'])
total_sum.to_csv('total_sum.txt',index=False, header = True, sep='\t')
价格有问题可以详谈哦