【C语言】数据结构链表问题
看别人设计的数据结构代码时遇到一个问题,需要帮忙理解一下。
背景:这是一个C语言,为管理音乐而开发的库
基本结构如下
typedef struct song Song;
typedef struct snode SNode;
typedef struct artist Artist;
struct song
{
Artist* artist;
char* title;
int index;
int playtimes;
};
struct snode
{
struct snode* next, * prev;
Song* song;
};
struct artist
{
char* name;
struct artist* next;
SNode* head, * tail;
};
下面是我理解不了的部分
//首先这个代码定义了两个全局的数列,我想知道这两个数列里面具体都有什么
Artist* artist_directory[NUM_CHARS];
SNode* index_directory[SIZE_INDEX_TABLE];
int num_index = 0;
Artist* add_artist(char* name)
{
// 已经用函数生成Artist了
Artist* ptr_artist = create_artist_instance(name); // create_artist_instance:初始化新的artist并返回
Artist* p = artist_directory[(unsigned char)name[0]]; // 这一句我不能理解,为什么用artist_directory[(unsigned char)name[0]]
// name[0]代表首字母但是为什么要用unsigned char,char型当index的意义是什么
Artist* q = NULL; // 在链表中跟随p,并记住p的位置
while (p != NULL && strcmp(p->name, name) < 0) // 主要list中,到比p小的值出现为止(为什么要这样,有特别原因吗?)
{ // 是不是将作者名字按照首字母大小排序
q = p;
p = p->next;
}
if (p == NULL && q == NULL) // 空list,也就是可以直接使用的点
{
artist_directory[(unsigned char)name[0]] = ptr_artist;
}
else if (q == NULL) // p在最前面的位置
{
ptr_artist->next = artist_directory[(unsigned char)name[0]]; //又出现这个
artist_directory[(unsigned char)name[0]] = ptr_artist;
}
else
{
ptr_artist->next = p;
q->next = ptr_artist;
}
return ptr_artist;
}
Artist* artist_directory[NUM_CHARS];
SNode* index_directory[SIZE_INDEX_TABLE];
artist_directory、index_directory这两个是指针数组,把他们当做数组来看待就行了,只是数组里面存放的元素有点特殊,不是一个值,而分别是指向Artist、SNode的指针,而Artist、SNode都是双向链表链表结构,从
typedef struct song Song;
typedef struct snode SNode;
typedef struct artist Artist;
可以看出。
结合变量的命名,也就可以看出artist_directory是一个存放Artist*指针的数组,数组的长度是NUM_CHARS,应该是首字符的总数,可能是ASCII码的长度,数组里面的元素分别存放着以A-Z开头的Artist链表指针,其中的链表指针分别指向name中某个字符开头的链表,这条链表里面存放的均是name以该字符为首的artist。
例如:
artist_directory[65] 即指向一条由所有name的首字符都是A开头的artist组成的链表。
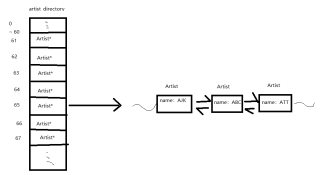
根据前面的解析应该就不难理解下面这行了
Artist* p = artist_directory[(unsigned char)name[0]];
至于
while (p != NULL && strcmp(p->name, name) < 0)
这个为什么要找到比的name的值刚好要小的p,首先可以看到这个函数的接口为add_artist,即向artist链表插入一个新的artist,结合前面分析,在前面已经找到了以name首字符的链表,这里再从找到的链表中找到比的name的值刚好要小的p,说明这要实现的功能是在链表中要按name的大小进行排序,name小的在链表前面,name大的在链表后面,方便后续查找。
这个数组,存的是结构体指针。
比如artist那个数组,就是存了一个个结构体artist的指针,也就是可以根据数组下标找到一个个结构体artist。而每一个artist都是链表 链表中放的是一个个name,可以根据结点的next域遍历找到每个name
就类似于二维数组 看成是一维数组的每个元素又是个一维数组。这个就是数组的每个元素是链表。当然是指针类型,省空间
//首先这个代码定义了两个全局的数列,我想知道这两个数列里面具体都有什么
Artist* artist_directory[NUM_CHARS]; /*如果art表示风格类型的话,这个数组就是记录风格类型的数组,如果art表示歌手的话,这就是歌手数组,它通过记录Artist指针来整体记录有多少风格类型,后面貌似是一风格类型首字母来分类风格类型,形成风格类型按字母分类的处理(这样便于查询分类)*/
SNode* index_directory[SIZE_INDEX_TABLE];/*类似上面的处理,这里可以看作是记录歌的数组,它也是通过记录SNode指针来整体记录有多少歌*/
int num_index = 0;
Artist* add_artist(char* name)
{
// 已经用函数生成Artist了
Artist* ptr_artist = create_artist_instance(name); // create_artist_instance:初始化新的artist并返回
Artist* p = artist_directory[(unsigned char)name[0]]; // 这一句我不能理解,为什么用artist_directory[(unsigned char)name[0]]
// name[0]代表首字母但是为什么要用unsigned char,char型当index的意义是什么
/*这样可以按字母分类,而且这里也支持所有可显示字符分类*/
Artist* q = NULL; // 在链表中跟随p,并记住p的位置
while (p != NULL && strcmp(p->name, name) < 0) // 主要list中,到比p小的值出现为止(为什么要这样,有特别原因吗?)
{ // 是不是将作者名字按照首字母大小排序
q = p;
p = p->next;
}
if (p == NULL && q == NULL) // 空list,也就是可以直接使用的点
{
artist_directory[(unsigned char)name[0]] = ptr_artist;
}
else if (q == NULL) // p在最前面的位置
{
ptr_artist->next = artist_directory[(unsigned char)name[0]]; //又出现这个 /*这个可以考虑为插入链表操作,把art具体对象插入到合适位置而已*/
artist_directory[(unsigned char)name[0]] = ptr_artist;
}
else
{
ptr_artist->next = p;
q->next = ptr_artist;
}
return ptr_artist;
}