两列时间序列数据怎么用apriori算法做关联分析呢?(语言-python)
问题遇到的现象和发生背景
就是两列时间序列数据怎么用apriori算法做关联分析呢?比如水位一列数据 位移一列数据 那怎么得出水位和位移这两个效应量关联度吗?
问题相关代码,请勿粘贴截图
Python 编程实现
运行结果及报错内容
我的解答思路和尝试过的方法
关联规则所使用的的Apriori算法要求输入的数据应为布尔类型吗?所以数值类型就要符号化?
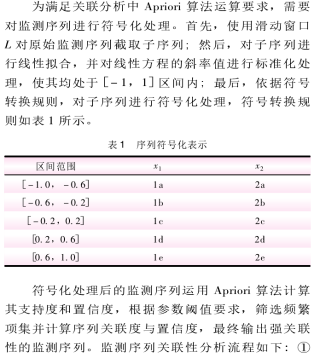
看到一篇文献是这样做的:原始数据—>滑动窗口L=10截取原始数据得到N个子序列—>线性拟合—>标准化斜率—>子序列符号化处理—>Apriori算法
搞不明白文中说从由每段斜率组成的事务集中找出频繁项集是什么意思?
我想要达到的结果
输出水位与位移这两监测效应量的关联性
原始数据—>滑动窗口L=10截取原始数据得到N个子序列—>线性拟合—>标准化斜率—>子序列符号化处理—>Apriori算法
我觉得这个说的挺清楚的啊,关联算法本身解决的是各个商品的关联度,其实就是分类变量的关联关系。所以这里不是转成布尔值,符号化处理是转成了分类量。所以这里的处理逻辑就是将原始数据按滑动窗口分成N个子序列(N个商品),线性拟合得出斜率(斜率是连续值通过符号化处理转成分类变量,相同的符号比如1a,1b ,就认为是同一个商品),然后就是典型的关联算法处理逻辑了
文献连接发下,
关联分析(Apriori)_上杉翔二的博客-CSDN博客 Apriori原理,Python实现。之前总结的典型关联分析是目标通过计算数据间的相关系数来寻找多维度数据的关系,但直观来讲,在实际生活中如果某一件事总是和另一件事同时出现,那么这两件事之间一定是有某种关系的,比如著名的啤酒和尿布。那么如何来寻找这种关系呢?既然是“同时出现”,那么关注点就应该着眼于这些“频繁项集合”(frequent item sets,经常在一起的物品集合)..........  https://blog.csdn.net/qq_39388410/article/details/78260262
https://blog.csdn.net/qq_39388410/article/details/78260262