loss函数只增不减
在使用Github:Semantic-Segmentation-Suite分割网络deeplab v3+模型进行数据集训练的时候遇到了loss函数只增不减的现象。
之前有用200张图片进行训练,结果没有出现问题,然后我通过旋转、镜像、平移和增加噪声的方式,将200张图片扩充到1000张,按照6:2:2的比例随机分配进行训练,发现测试的时候分割结果为全黑,loss函数只增不减,请问这是遇到什么问题了
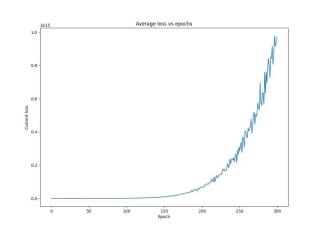
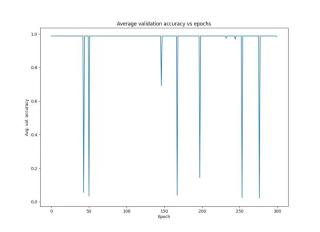
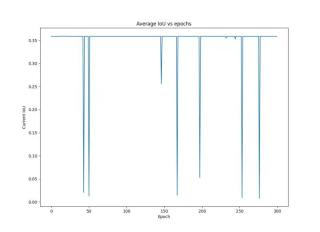
训练集的loss在训练过程中迟迟不下降,一般是由这几个方面导致的。
1.模型结构和特征工程存在问题
如果一个模型的结构有问题,那么它就很难训练,通常,自己“自主研发”设计的网络结构可能很难适应实际问题,通过参考别人已经设计好并实现和测试过的结构,以及特征工程方案,进行改进和适应性修改,可以更快更好的完成目标任务。当模型结构不好或者规模太小、特征工程存在问题时,其对于数据的拟合能力不足,是很多人在进行一个新的研究或者工程应用时,遇到的第一个大问题。
比如我在搭建wavnet时,其中res_block的输出给错了,导致网络很难训练的问题。
2.权重初始化方案有问题
神经网络在训练之前,我们需要给其赋予一个初值,但是如何选择这个初始值,则要参考相关文献资料,选择一个最合适的初始化方案。常用的初始化方案有全零初始化、随机正态分布初始化和随机均匀分布初始化等。合适的初始化方案很重要,用对了,事半功倍,用不对,模型训练状况不忍直视。博主之前训练一个模型,初始化方案不对,训练半天都训练不动,loss值迟迟居高不下,最后改了初始化方案,loss值就如断崖式下降。
建议无脑xaiver normal初始化或者 he normal
3.正则化过度
L1 L2和Dropout是防止过拟合用的,当训练集loss下不来时,就要考虑一下是不是正则化过度,导致模型欠拟合了。一般在刚开始是不需要加正则化的,过拟合后,再根据训练情况进行调整。如果一开始就正则化,那么就难以确定当前的模型结构设计是否正确了,而且调试起来也更加困难。
建议bn,他也有一定的防止过拟合的能力
4.选择合适的激活函数、损失函数
不仅仅是初始化,在神经网络的激活函数、损失函数方面的选取,也是需要根据任务类型,选取最合适的。
比如,卷积神经网络中,卷积层的输出,一般使用ReLu作为激活函数,因为可以有效避免梯度消失,并且线性函数在计算性能上面更加有优势。而循环神经网络中的循环层一般为tanh,或者ReLu,全连接层也多用ReLu,只有在神经网络的输出层,使用全连接层来分类的情况下,才会使用softmax这种激活函数。
而损失函数,对于一些分类任务,通常使用交叉熵损失函数,回归任务使用均方误差,有自动对齐的任务使用CTC loss等。损失函数相当于模型拟合程度的一个评价指标,这个指标的结果越小越好。一个好的损失函数,可以在神经网络优化时,产生更好的模型参数。
5.选择合适的优化器和学习速率
神经网络的优化器选取一般选取Adam,但是在有些情况下Adam难以训练,这时候需要使用如SGD之类的其他优化器。学习率决定了网络训练的速度,但学习率不是越大越好,当网络趋近于收敛时应该选择较小的学习率来保证找到更好的最优点。所以,我们需要手动调整学习率,首先选择一个合适的初始学习率,当训练不动之后,稍微降低学习率,然后再训练一段时间,这时候基本上就完全收敛了。一般学习率的调整是乘以/除以10的倍数。不过现在也有一些自动调整学习率的方案了,不过,我们也要知道如何手动调整到合适的学习率。
6.训练时间不足
我有时会遇到有人问这样的问题,为什么训练了好几个小时了,怎么loss没降多少,或者怎么还没收敛。心急吃不了热豆腐!各种深度学习的训练都有不同的计算量,当需要的计算量很大时,怎么可能几个小时就训练完,尤其是还在使用自己的个人电脑CPU来训练模型的情况下。一般解决方案就是,使用更快的硬件加速训练,比如GPU,在涉及到计算机视觉方面的任务时,加速效果显著,主要是卷积网络的缘故。当已经没有办法使用硬件来加速的时候,唯一的解决方案就是——等。
7.模型训练遇到瓶颈
8.batch size过大
9.数据集未打乱
10.数据集有问题
11.未进行归一化
12.特征工程中对数据特征的选取有问题

一个数据集噪声过多,或者数据标注有大量错误时,神经网络难以从中学到有用的信息
分割结果全黑了怎么学习特征