关于#java#的问题:利用IDEA编写mapreduce程序,统计一篇英文文章各个单词出现次数
利用IDEA编写mapreduce程序,统计一篇英文文章各个单词出现次数,并将结果输出到linux本地(/home/usr这种),输出结果格式为 (单词)出现次数为( )次
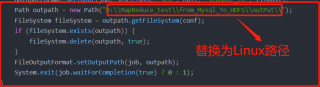
按照图片中的写法,试一下!
```java
Mapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMap extends Mapper<LongWritable, Text,Text,IntWritable> {
Text text=new Text();
IntWritable intWritable=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] s = value.toString().split(" ");
for(String word :s ){
text.set(word);
context.write(text,intWritable);
}
}
}
Reducer
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReduce extends Reducer<Text, IntWritable,Text, IntWritable> {
int sum;
IntWritable intWritable=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
sum=0;
for (IntWritable i:values){
sum+= i.get();
}
intWritable.set(sum);
context.write(key,intWritable);
}
}
Driver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws Exception {
Configuration con = new Configuration();
Job job= Job.getInstance(con);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path("in/word.txt"));
FileOutputFormat.setOutputPath(job,new Path("in/outWord.txt"));
FileSystem fileSystem=FileSystem.get(new Path("in/outWord.txt").toUri(),con);
if(fileSystem.exists(new Path("in/outWord.txt"))){
fileSystem.delete(new Path("in/outWord.txt"),true);
}
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
输入输出的文件路径在当前项目下建既可
```
代码发出来看看
是要实现这个功能吗
如何编写一个MapReduce程序统计每个单词出现次数
https://blog.csdn.net/weixin_46005650/article/details/123865709