SqlServer order desc查询慢
现在我有几个表的数据要联合起来查询求得最新的数据 每张表的数据都在10w条左右,
我需要通过time字段获取最新的一条数据,
但是我在查询的过程中发现加上了desc 之后数据查询第一次就会很慢,达到了18s ,但是往后查询之后都是几十毫秒,在表中有建立用到的索引,
因为这些数据都要进行实时更新的,第一次运行很影响用户体验,想问一下有没有优化策略
这个是第一次查询的结果 运行结果为18s
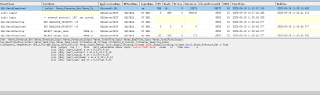
这个是第二次运行的结果 运行结果为0.1s

这里所有要查询的列名都是动态列
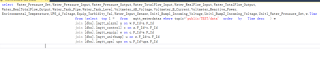
如果用time字段的表本来自带自增主键id,且id自动按time从旧往新的顺序保持增加的话,在where子句中用限定id范围的方法代替限定time范围的方法,速度会快很多。
你可能又要问,怎么获取time范围对应的id范围?
答:
1.对id使用二分法
2.time和id的对应不用太精确
程序单独 把最新一条数据存在一个表里面
还有一种把时间格式改成存时间戳试试
1、首先需要进行业务分析:你需要的mqtt_waterdatas表的满足 topic = 'public/TEST/data' 条件的数据是否每天都会有?比如每天都有实时业务且实时更新或凌晨定时同步等,这涉及到使用该查询的人是早于当天数据生成时间还是晚于当天数据生成时间查询数据的问题
2、其次进行表索引建立:针对上述因素,可对topic和time字段建立联合索引,其实有了索引查询就会快很多(顺便一提,你第二次查询快是因为数据库系统都有缓存,间隔时间短的查询,绝大部分都是从缓存提取的数据)
3、最后进行SQL优化调整:如果建立了索引还是不行,就需要利用业务分析的结果,如果每天都有数据,那在WHERE条件中增加time条件:time > convert( date, getdate( ) );如果是 XX天(XX小时内类似)内必然有数据,就写为:time > DATEADD( dd, -xx, convert( date, getdate( ) ) ),这样会极大的减少排序的数据量,从而节省排序的时间
time建立索引
如果这个time是记录添加时间,且id是自增的话,可以使用id去进行排序查询取最新的一条