python 如何按照标签分割、合并xml文件
问题遇到的现象和发生背景
先放xml文件截图
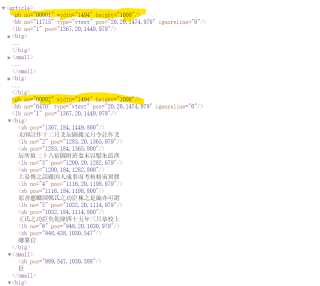
我希望能够从第二个pb开始,分成两个xml文件,然后我再将两个文件用dom处理完后(dom方法处理文件不是我要问的问题),将其合成一个文件
问题相关代码,请勿粘贴截图
我在分割代码的时候,用了正则和字符串的分割,但是并没有达成我的效果
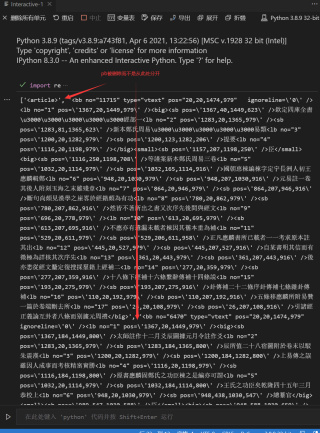
以下是我写的代码
import re
import traceback
def readXml(filepath):
try:
#不要把open放在try中,以防止打开失败,那么就不用关闭了
file_object = open(filepath,"rb")
#file_context是一个string,读取完后,就失去了对test.txt的文件引用
file_context = file_object.read().decode('utf-8')
file_object.close()
return file_context
except:
traceback.print_exc()
#print("出现异常,没有文件。")
return ""
root = readXml("E:\Python\Test\data\86B16D05_AD4C_4C1F_A7B6_76672C3B1A27\C_00000.xml")
# print(root)
strPb = re.split('<pb no=\"000[0-9]{2}\" width=\"1494\" height=\"1000\" />',root)
print(strPb)
运行结果及报错内容
我的解答思路和尝试过的方法
我尝试了用字符串读取的方法,但我觉得这样行不通,还有别的方法能够打成吗?
我想要达到的结果
1、我希望能够按照pb处将其分割成多个文件,两个pb之间的内容是一个文件,
2、在分成多个xml之后,我要用dom处理,处理完后我希望能够将它们再合并回去,合并成原来结构的xml
3、能否尽量用dom方法或者字符串正则方法
万分感谢
如果只是去除特定的字符串,用re.sub替换掉试试,例如:
import re
import xml.etree.ElementTree as ET
from xml.dom import minidom
s = '''<article><pb pos="1"><ab>vtext</ab><bb no="123">1</bb></pb><pb pos="2"><ab>vtext1</ab><bb no="457">2</bb></pb></article>'''
rf=re.sub('<pb pos="\d+">','',s)
rs=re.sub('</pb>','',rf)
dom = minidom.parseString(rs)
with open('a.xml', 'w') as f:
dom.writexml(f, "",'\t',newl="\n",encoding='utf-8')
你题目的解答代码如下:
import re
root = '''
<article>
<pb no="00001" width="1494" height="1000" />
<xxxx>1</xxxx>
<xxxx>2</xxxx>
<pb no="00002" width="1494" height="1000" />
<xxxx>3</xxxx>
<xxxx>4</xxxx>
<xxxx>5</xxxx>
<pb no="00003" width="1494" height="1000" />
<xxxx>6</xxxx>
<xxxx>7</xxxx>
</article>
'''
d = re.split(r'(<pb no="\d+" width="1494" height="1000" />)',root)
li = []
si = 0
for ei in range(3,len(d)+1,2):
li.append("".join(d[si:ei]))
si = ei
print(li)
您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!如有帮助,请点击我的回答下方的【采纳该答案】按钮帮忙采纳下,谢谢!

PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632