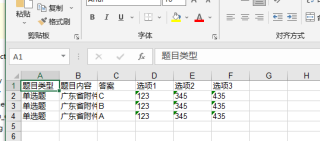
有没有人帮我改一下代码 要求如第一个图所示的样式
import xlwt
f=open(r'D:\单选题.txt.txt',encoding='utf-8')
wb = xlwt.Workbook(encoding = 'utf-8')
ws1 = wb.add_sheet('first')
ws1.write(0,0,'题目类型')
ws1.write(0,1,'题目内容')
ws1.write(0,2,'答案')
ws1.write(0,3,'选项1')
ws1.write(0,4,'选项2')
ws1.write(0,5,'选项3')
row = 1
col = 0
k = 1
for lines in f:
a = lines.split(',')
k+=1
for i in range(len(a)):
ws1.write(row, col ,a[i])
col += 1
row += 1
col = 0
wb.save(r"单选题.xls")

要求改为如图所示的样式 而我的为什么不出结果
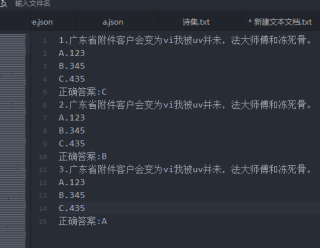
txt文件如下图所示

看效果图可知:
- 你需要匹配每一道题的标题 可以使用正则表达式 从"n."到"。"结束
- 答案选项从"[ABC]."到换行符结束
- 答案:正确答案:[ABC]
然后循环既可以得到并写入excl中
import xlwt
import re
with open(r'D:\单选题.txt',encoding='utf-8') as f:
txt = f.read()
wb = xlwt.Workbook(encoding = 'utf-8')
ws1 = wb.add_sheet('first')
ws1.write(0,0,'题目类型')
ws1.write(0,1,'题目内容')
ws1.write(0,2,'答案')
ws1.write(0,3,'选项1')
ws1.write(0,4,'选项2')
ws1.write(0,5,'选项3')
row = 1
col = 0
k = 1
print(txt)
lines = re.findall(r"[\d]\.(.*?。)", txt, re.I | re.S)
ans1 = re.findall(r"A\.(.*?)\n", txt, re.I | re.S)
ans2 = re.findall(r"B\.(.*?)\n", txt, re.I | re.S)
ans3 = re.findall(r"C\.(.*?)\n", txt, re.I | re.S)
print(lines)
print(ans1)
print(ans2)
print(ans3)
ans_true = re.findall(r"正确答案:([A-Z])", txt, re.I | re.S)
row = 1
for i in range(len(lines)):
ws1.write(row, 0, '单选题')
ws1.write(row, 1, lines[i])
ws1.write(row, 2, ans_true[i])
ws1.write(row, 3, ans1[i])
ws1.write(row, 4, ans2[i])
ws1.write(row, 5, ans3[i])
row += 1
wb.save(r"单选题.xls")
import xlwt
f=open(r'D:\单选题.txt.txt',encoding='utf-8')
wb = xlwt.Workbook(encoding = 'utf-8')
ws1 = wb.add_sheet('first')
ws1.write(0,0,'题目类型')
ws1.write(0,1,'题目内容')
ws1.write(0,2,'答案')
ws1.write(0,3,'选项1')
ws1.write(0,4,'选项2')
ws1.write(0,5,'选项3')
row = 1
col = 0
lines = f.readline()
while lines:
col += 1
ws1.write(row, col ,lines)
if col >= 5:
col = 0
row += 1
lines = f.readline()
wb.save(r"单选题.xls")