python实现大商所保证金优惠参数表下载,总是找不到元素
工作需要,每天都要去大商所的官网下载保证金优惠参数表,现在每天收工下载太麻烦了,于是想写个python脚本每天自己下载。
没有html的任何经验,在网上边搜边写
获取保证金优惠参数表的url如下 http://www.dce.com.cn/dalianshangpin/yw/fw/ywcs/jycs/tlbzjyhcs/index.html
from selenium import webdriver
import time
import os
url='http://www.dce.com.cn/dalianshangpin/yw/fw/ywcs/jycs/tlbzjyhcs/index.html'
driver = webdriver.Chrome()
driver.get(url)
time.sleep(5)
iframe=driver.find_element_by_tag_name('iframe')
time.sleep(2)
driver.switch_to.frame(iframe)
time.sleep(2)
driver.find_element_by_xpath('//*[@id="marginArbiPerfParaForm"]/div/ul/li[3]/a').click()
我需要使用「组合保证金优惠参数 导出文本」这个按钮,代码思路,打开网页之后,切换到iframe中,通过xpath找到箭头处的按钮,调用click方法模拟点击,xpath是通过chrome的元素检查,右键copy Xpath出来的。但是运行就会报找不到元素,不知道是哪里出了问题。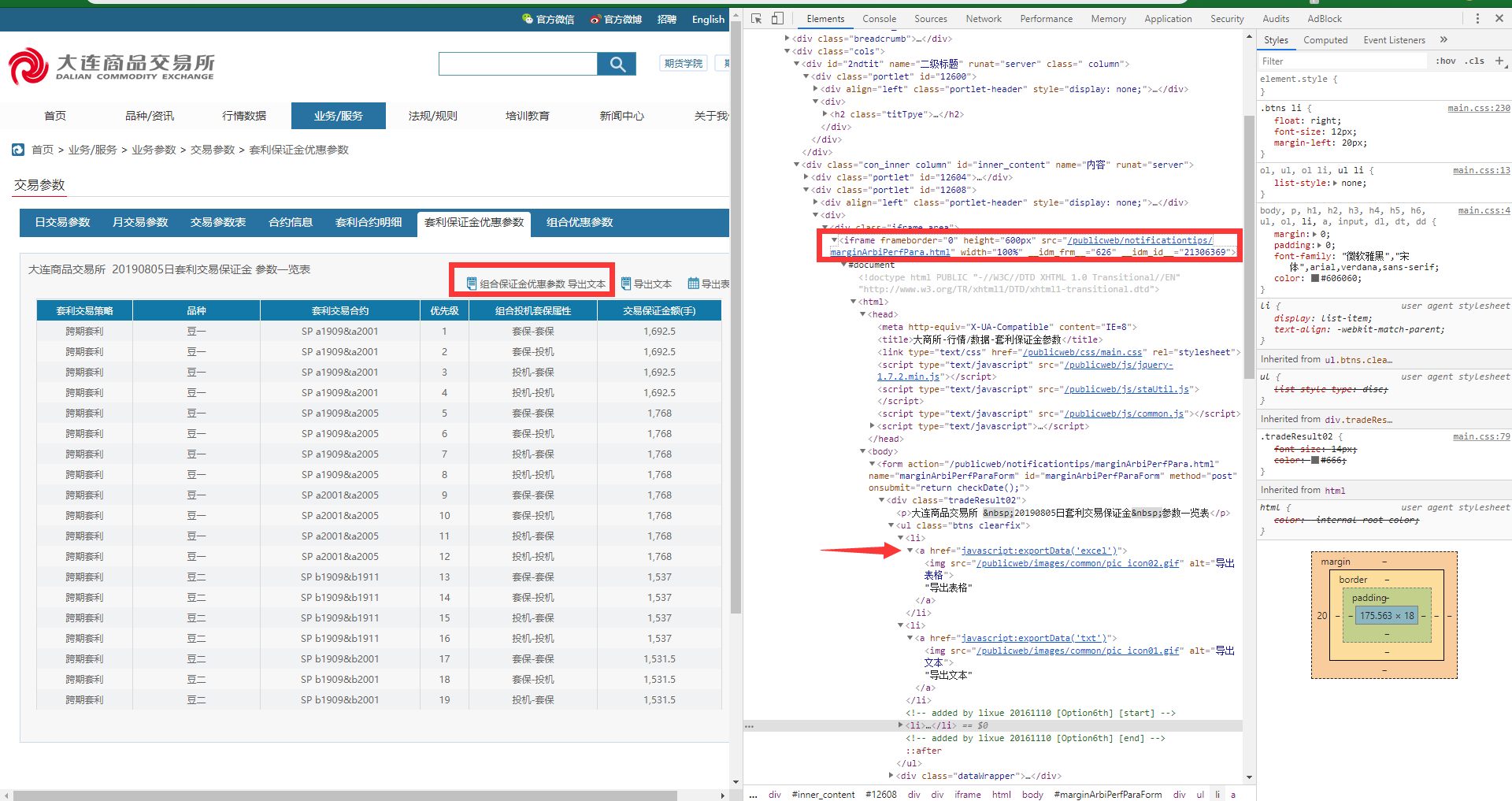
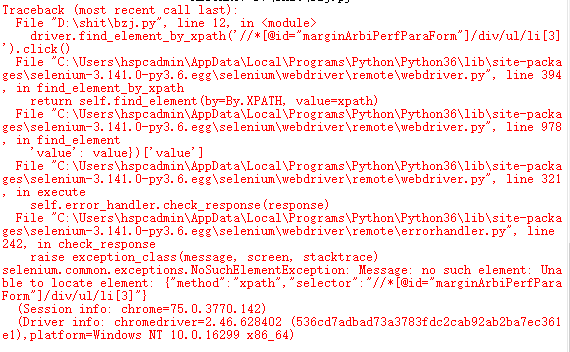
哥们,你知道我花了多少时间去分析吗
这个页面我找到了三个iframe标签,你需要的东西在第三个iframe标签上
所以
iframe=driver.find_elements_by_tag_name('iframe')[2]
你这个没必要用selenium, 做爬虫不到万不得已不会用这玩意,效率太低. 如果针对你的代码问题, 确实是iframe的定位出了问题.
分析请求行为, 用requets就可以解决问题. 代码如下:
import requests
from lxml import etree
import csv
url = 'http://www.dce.com.cn/publicweb/notificationtips/marginArbiPerfPara.html'
headers = {
'Referer': 'http://www.dce.com.cn/dalianshangpin/yw/fw/ywcs/jycs/tlbzjyhcs/index.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
res = requests.get(url, headers=headers)
html = etree.HTML(res.content.decode())
tr_list = html.xpath('//div[@class="dataWrapper"]//tr')
data = []
for tr in tr_list:
td_list = tr.xpath('./td')
items = []
for td in td_list:
field = td.xpath('./text()')[0]
items.append(field)
data.append(items)
with open('套利保证金.csv','w',encoding='gbk',newline='') as f:
fw = csv.writer(f)
fw.writerows(data)