如何提取XML这里的东西?
python爬取58同城的数据,得到的结果房价和面积被加密,通过百度知道它的形成过程
和原来的破解过程,但是现在有了一点点小变动,我想如何提取这段name和code
的值,求教!!!!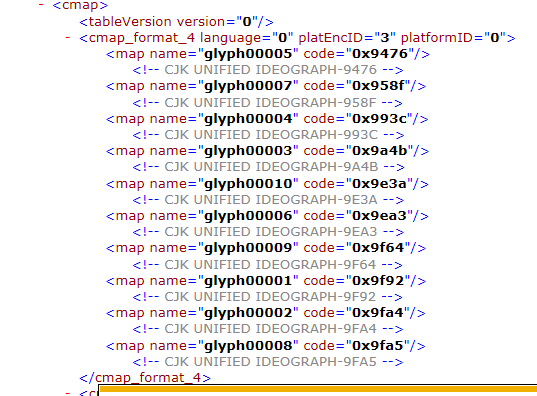
我想把map name对应的值和其code的值 如何提取出来。
在FontTools.ttLib里面 好像没有提取map的函数吧?
之前代码:
import base64
from io import BytesIO
from fontTools.ttLib import TTFont
import requests
import re
from lxml import etree
for i in range(1,3):
url = 'https://sz.58.com/zufang/pn'+str(i)
res = requests.get(url)
#print(res.text)
bs64_str = re.findall("charset=utf-8;base64,(.*?)'\)", res.text)[0]
bin_data = base64.decodebytes(bs64_str.encode())
with open('test'+str(i)+'.otf','wb') as f:
f.write(bin_data)
font = TTFont(BytesIO(bin_data))
font.saveXML('test'+str(i)+'.xml')
uniList = font['glyf'].keys()
c = font['cmap'].tables[0].ttFont.tables['cmap'].tables[0].cmap
结果为{38006: 'glyph00005', 38287: 'glyph00007', 39228: 'glyph00004', 39499: 'glyph00003', 40506: 'glyph00010', 40611: 'glyph00006', 40804: 'glyph00009', 40850: 'glyph00001', 40868: 'glyph00002', 40869: 'glyph00008'}
{38006: 'glyph00009', 38287: 'glyph00003', 39228: 'glyph00005', 39499: 'glyph00001', 40506: 'glyph00006', 40611: 'glyph00002', 40804: 'glyph00010', 40850: 'glyph00008', 40868: 'glyph00004', 40869: 'glyph00007'}
所以我如何提取图片中map name和code所对应的值?
from lxml import etree
parser = etree.HTMLParser(encoding="utf-8")
xml = etree.parse('test1.xml',parser=parser) # etree加载本地XML文件,以第1个为例('test1.xml')
name_list = xml.xpath('//cmap//map/@name') # 获取name值
code_list = xml.xpath('//cmap//map/@code') # 获取code值
code_list = [int(i, 16) for i in code_list] # code值16进制转10进制
print(dict(zip(code_list, name_list)))
望采纳!