PDF识别,字符串切割
利润及利润分配表 编制单位:* 年度 单位:元 项 行次 本年累计数 上年累计数 一、主营业务收入 一 1(,206(,018(,984.66 1(,020(,275(,643.16 减:主营业务成本 2 1(,036(,254(,056.12 905(,868(,069.65 主营业务税金及附加 3 2(,201(,041.98 2(,799(,152.06 二、主营业务利润(亏损以“一”号填列) 4 167(,563(,886.56 111(,608(,421.45 加:其他业务利润(亏损以“一”号填列) 5 减:销售费用 6 85(,435(,606.72 58.425.317.15 管理费用 7 57(,771(,160.54 31.023.864.04 财务费用 8 3.962(,380.62 2,406,166.42 资产减值损失 三 、营业利润(亏损以“一”号填列) 9 20(,394(,738.68 19,753.073.84 加:投资收益(损失以“一”号填列) 10 补贴收入 11 营业外收入 12 526(,003.65 2(,088,325.25 减:营业外支出 13 3(,989(,598.36 4(,621.874.56 四、利润总额(亏损以“一”号填列) 14 16(,931(,143.97 17(,219(,524.53 减:所得税 15 2(,052(,603.69 2.582(,928.68 少数股东权益 16 五、净利润(亏损以“一”号填列) 17 14.878.540.28 14(,636(,595.85 加:以前年度损益调整 18 -3(,172(,865.39 年初未分配利润 19 244(,420(,327.42 238(,315(,936.41 其他转入 六、可供分配的利润 20 256(,126(,002.31 252.952.532.26 减:提取法定盈余公积 21 3(,247(,119.32 8.532(,204.84 提取法定公益金 22 - 提取职工奖励及福利基金 23 提取储备基金 24 提取企业发展基金 25 利润归还投资 26 七、可供投资者分配的利润 27 252(,878(,882.99 244(,420(,327. 减:应付优先股股利 28 提取任意盈余公积 29 0p01965 应付普通股股利 30 转作资本(或股本)的普通股股利 31 心 八、未分配利润 32 252(,878(,882.99 244(,420(,327.42
(CSDN不可输入同样符号,所以,替换为(,)

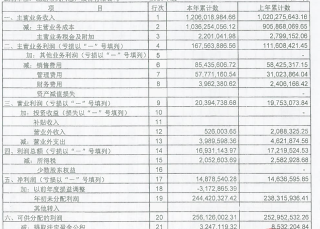
一串从PDF识别出来的字符串如何照PDF按行进行切割
用字符串不好处理,并不知道分隔符是什么。
用读取表格方法进行读取。
import com.spire.pdf.*;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
public class ExtractTable {
public static void main(String[] args)throws IOException {
//加载PDF文档
PdfDocument pdf = new PdfDocument();
//pdf.loadFromFile("test.pdf");
URL url = new URL("https://res.ygyg.cn/userbusipub/M00/14/AC/CicmImJ7DcmAfB6vAAQLhfInluc603.pdf");
//打开链接
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
//设置请求方式为"GET"
conn.setRequestMethod("GET");
//超时响应时间为5秒
conn.setConnectTimeout(5 * 1000);
//通过输入流获取图片数据
InputStream inStream = conn.getInputStream();
pdf.loadFromStream(inStream);
//创建StringBuilder类的实例
StringBuilder builder = new StringBuilder();
//抽取表格
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists ;
for (int page = 0; page < pdf.getPages().getCount(); page++)
{
tableLists = extractor.extractTable(page);
if (tableLists != null && tableLists.length > 0)
{
for (PdfTable table : tableLists)
{
int row = table.getRowCount();
int column = table.getColumnCount();
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
String text = table.getText(i, j);
builder.append(text+" ");
}
builder.append("\r\n");
}
}
}
}
//控制台输出
System.out.println(builder.toString());
//将提取的表格内容写入txt文档
FileWriter fileWriter = new FileWriter("ExtractedTable.txt");
fileWriter.write(builder.toString());
fileWriter.flush();
fileWriter.close();
}
}
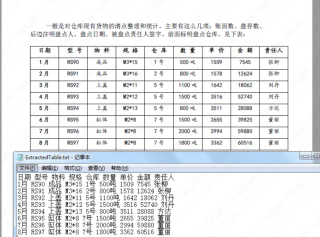
首先用大写的一二三四五六分隔为行,再用逗号分隔,然后对后面的数据进行处理。
建议直接进行pad按行识别字符然后转excel,有帮助请点击右上角的采纳,有疑问或问题欢迎继续讨论
import pdfplumber
import xlwt
# 定义保存Excel的位置
workbook = xlwt.Workbook() #定义workbook
sheet = workbook.add_sheet('Sheet1') #添加sheet
i = 0 # Excel起始位置
# path = input("请输入PDF文件位置:")
path = "CicmImJ7DcmAfB6vAAQLhfInluc603.pdf" # 导入PDF路径
pdf = pdfplumber.open(path)
print('\n')
print('开始读取数据')
print('\n')
for page in pdf.pages:
# 获取当前页面的全部文本信息,包括表格中的文字
# print(page.extract_text())
for table in page.extract_tables():
# print(table)
# 按行遍历pdf表格
for row in table:
# 打印数据
print(row)
# # 写入excel
for j in range(len(row)):
sheet.write(i, j, row[j])
i += 1
print("读取完成")
print('---------- 分割线 ----------')
pdf.close()
# 保存Excel表
workbook.save('PDFresult.xls')
print('\n')
print('写入excel成功')
print('保存位置:')
print('PDFresult.xls')
print('\n')
input('PDF取读完毕,按任意键退出')
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632