设计python爬虫,可是只爬取了index标签,不知道怎么回事
问题遇到的现象和发生背景
pycharm中爬虫设计,不能爬取理想的内容
问题相关代码,请勿粘贴截图
import time
import requests
import json
from lxml import etree
def get_page(url): #请求页面数据
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36'
}
res =requests.get(url, headers=headers)
if res.status_code == 200:
return res.text
else:
return False
except:
return False
def parse_page(html): #解析页面数据
html = etree.HTML(html)
titles = html.xpath('//div[@class="titles"]')
for title in titles:
res = {
'index':title.xpath('.//*[@id="topiclist1"]/ul/li/div/a')
}
yield res
def write_file(item): #写入页面数据
with open('./gongkong.json','a',encoding='utf-8') as fp:
fp.write(json.dumps(item,ensure_ascii=False))
fp.write('\n')
def main(i):
url = f'http://bbs.gongkong.com/product/plc-1-1_{i}.htm'
html = get_page(url)
print(f'正在解析url:{url}')
if html:
for title in parse_page(html):
print(f'正在写入数据{title}')
write_file(item=title)
if __name__ == '__main__':
for i in range(1,11):
main(i)
time.sleep(2)
运行结果及报错内容
爬取的json文件仅仅是一堆标签
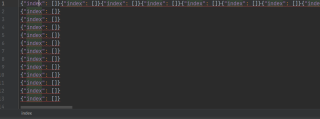
我的解答思路和尝试过的方法
没有思路
我想要达到的结果
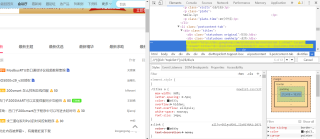
我copy的应该是超链接里的内容的xpath,可是爬取的结果没有任何有效文字
没看网站,尝试xpath里加个/text()