爬虫爬取<p>和<p,title='...'>中所有<p>的标签?
大神,小白请教用正则或者beautifulsoup找到<p中的内容
不知道如何复制源码,这上面显示中文,标签都被省略了,抱歉,xie'xie'da'jia
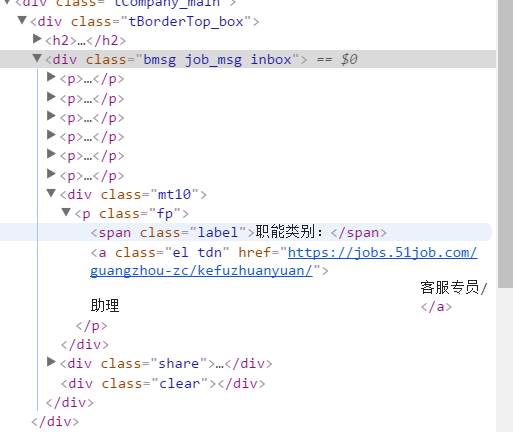
没看到title
soup.select('p[class="fp"]')[1].text
这个可以得到"客服专员/助理"
你需要的是xpath,随便给你找了一篇文章
https://www.cnblogs.com/lei0213/p/7506130.html
大神,小白请教用正则或者beautifulsoup找到<p中的内容
不知道如何复制源码,这上面显示中文,标签都被省略了,抱歉,xie'xie'da'jia
没看到title
soup.select('p[class="fp"]')[1].text
这个可以得到"客服专员/助理"
你需要的是xpath,随便给你找了一篇文章
https://www.cnblogs.com/lei0213/p/7506130.html