scrapy 在process_response中返回request 异常
背景
在我爬一个网站的时候 这个网站的一个反爬措施是 同一ip检测到一分钟额你请求频率过高 就会返回一个 文字点选的验证码 持续十分钟,十分钟之后就 正常请求。
措施
因为验证码只持续十分钟 所以我选择等待十分钟
我在process_response中判断
if "人机认证" in response.text:
while True:
# 循环的用requests模块去请求url 如果没有验证码了就退出循环
if "人机认证" in requests.get("url").text:
time.sleep(60)
else:
break
return request
问题
在我测试的过程中 出现验证码后 我就去浏览器 通过文字点选验证码 按道理说,在等待一分钟后,程序就离开阻塞 ,正常运行起来。然后情况却是依然不断的有日志表示 response中有人机认证
另外我发现一个问题 在正常的scrapy请求的时候 日志中会有一条相关日志
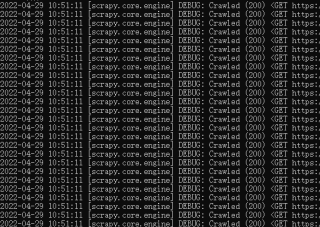
然而在我的问题中却并没有scrapy请求日志
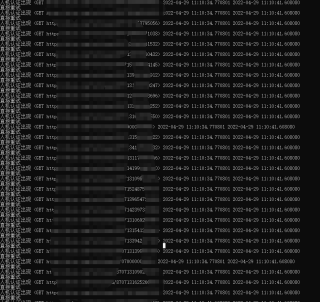
代码
作为参考附上我的代码:
class *************oaderMiddleware3:
def process_request(self, request, spider):
request.meta['update_time'] = spider.update_time
return None
def process_response(self, request, response, spider):
if "人机认证" in response.text:
print("人机认证出现", request, request.meta.get("update_time"),spider.update_time)
if request.meta.get('update_time') != spider.update_time:
print("直接重试")
return request
while True:
if "人机认证" in requests.get("https://***********54869574").text:
time.sleep(1)
else:
spider.update_time = datetime.datetime.now()
print("认证通过", spider.update_time, datetime.datetime.now())
time.sleep(5)
break
return request
return response