java多线程批量插入数据报错
问题是这样的,我们有一个业务场景支持excel 批量导入上千条数据,且需要支持整批同时成功或失败,于是我打算将连接改成不自动提交,以手工开启事务形式处理,代码如下
ExecutorService service = Executors.newFixedThreadPool(5);
@Resource
SqlSession sqlSession;
@Test
public void batchInsert() throws SQLException {
Connection connection = sqlSession.getConnection();
try {
// 设置手动提交
connection.setAutoCommit(false);
StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);
//执行子线程
Student stu1 = new Student("张三");
Student stu2 = new Student("李四");
Student stu3 = new Student("王五");
List<Student> students= Arrays.asList(stu1,stu2,stu3);
List<Callable<Integer>> callableList = new ArrayList<>();
for (Student student : students) {
Callable<Integer> callable=()-> studentMapper.addStudent(student);
callableList.add(callable);
}
List<Future<Integer>> futures = service.invokeAll(callableList);
for (Future<Integer> future:futures) {
if (future.get()<=0){
connection.rollback();
return;
}
}
connection.commit();
System.out.println("添加完毕");
}catch (Exception e){
connection.rollback();
log.info("error",e);
throw new RuntimeException("002出现异常");
}
Scanner scanner=new Scanner(System.in);
scanner.next();
}
mysq和mybatis 配置如下
@Bean("masterDataSource")
@Primary
public DataSource masterDatasource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName(driver);
dataSource.setUrl(url);
dataSource.setUsername(userName);
dataSource.setPassword(password);
dataSource.setRemoveAbandonedTimeoutMillis(10*1000);
dataSource.setRemoveAbandoned(true);
dataSource.setTimeBetweenConnectErrorMillis(10*1000);
return dataSource;
}
/***
* 管理事务
*
* */
@Bean(name = "masterTransactionManager")
@Primary
public DataSourceTransactionManager masterTransactionManager() {
return new DataSourceTransactionManager(masterDatasource());
}
/***
* 创建sqlsessionFactory
*
* */
@Bean(name = "masterSqlSessionFactory")
@Primary
public SqlSessionFactory masterSqlSessionFactory(@Qualifier("masterDataSource") DataSource masterDataSource)
throws Exception {
final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(masterDataSource);
org.apache.ibatis.session.Configuration config = new org.apache.ibatis.session.Configuration();
config.setMapUnderscoreToCamelCase(true);
sessionFactory.setConfiguration(config);
sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources(MAPPER_LOCAL));
sessionFactory.setPlugins(new SqlCostInterceptor(),new GlobalInterceptor());
return sessionFactory.getObject();
}
但现实很残酷,报错了
java.sql.SQLException: connection holder is null
at com.alibaba.druid.pool.DruidPooledConnection.checkStateInternal(DruidPooledConnection.java:1157)
at com.alibaba.druid.pool.DruidPooledConnection.checkState(DruidPooledConnection.java:1148)
at com.alibaba.druid.pool.DruidPooledConnection.commit(DruidPooledConnection.java:743)
如果你是springboot项目,像你说的那个批量处理数据什么的,你就用他自带的多线程方法ThreadPoolTaskExecutor,去处理,最后.join的方式加入到主线程,你只需要处理数据网数据库查的操作就行,ThreadPoolTaskExecutor的使用方式b站上有《SpringBoot项目如何使用线程池提升业务速度?》里面有这个的使用方式,是一个大佬老杨做的视频,视频时长2分零7秒,可以学习使用一下,像多线程挂钩的,很多现在都封装好的方式,没必要自己写代码,只需要完成业务逻辑就行
大批量数据库插入 使用sqlbulkcopy 试试
手动删除数据也可以
应该挺多答案的,connection holder is Null ,大概率是事务时间太长被回收了,可以尝试调大removeAbandonedTimeout
报这个错误是因为超时时间比sql实际执行时间要短。
需要调整参数设置,比如AbandonedTimeout等,把所有相关的timeout时间设置足够长即可。
如有帮助,请采纳,十分感谢!
https://blog.csdn.net/weixin_45528650/article/details/115978222
看看这个呢
执行时间是否超过了10秒,调大
超时时间设置长一点
或者你思路错了呢 为什么不可以使用批量插入呢? 问中也没有说是高并发场景 且楼主觉得这种方式真的合理吗?
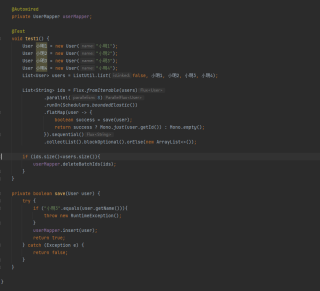
首先你可以尝试在catch后加上finally模块,用于判断connect是否为null,然后进行关闭的判断,如果还是不行,建议使用批量插入的逻辑,我们项目中就是这样实现的,具体是将导入的数据分批次,一次批量执行一百条数据,不会超过sql的最大长度,对于你的上千条数据十几次就执行完了,效率不会低的,我们导入时涉及到上万条数据,几十秒就结束了
我做过一个这样的相关场景你可以看看,我的是非结构化转结构化数据,开启线程池批量处理要么都成功要么都失败,你可以看看我的博客https://blog.csdn.net/qq_41973632/article/details/122490990?spm=1001.2014.3001.5502