协同过滤稀疏矩阵预测值问题
问题
在做协同过滤有关的论文实验时,由于数据集比较稀疏,在利用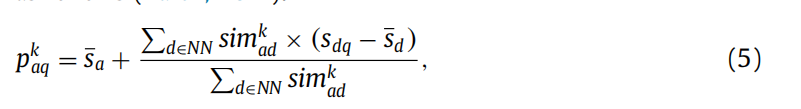
计算预测值时发现由于本身的评分矩阵比较稀疏,分母过小分子过大,预测值普遍偏小,在进行0-1分类的阈值设置上比较麻烦,想问一下有什么方法能对这种情况进行改进
https://blog.csdn.net/chaiqunxing51/article/details/50977195
在做协同过滤有关的论文实验时,由于数据集比较稀疏,在利用
计算预测值时发现由于本身的评分矩阵比较稀疏,分母过小分子过大,预测值普遍偏小,在进行0-1分类的阈值设置上比较麻烦,想问一下有什么方法能对这种情况进行改进
https://blog.csdn.net/chaiqunxing51/article/details/50977195