关于爬虫爬取动态网站的问题
本人用BeautifulSoup爬取一个网站内容,但是操作中发现,网页下滑会加载新的内容,致使爬取信息不完整。想请问如何可以解决?
代码如下:
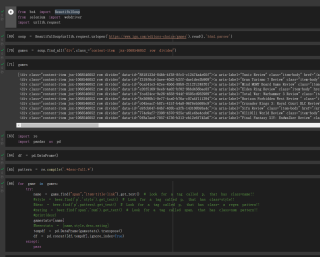
你这个网页中的内容通过 js代码读取外部json数据来动态更新的。
可以通过F12控制台分析页面数据加载的链接,找到真正json数据的地址进行爬取。

让页面滚动底部加载了更多数据之后再获取
您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!如有帮助,请点击我的回答下方的【采纳该答案】按钮帮忙采纳下,谢谢!

PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632