python爬取跳页url不变的网页表格数据
小白一个,刚学python爬虫1天,因为跟朋友夸下海口说简单的都会,但我这个就不会了。
具体需求:python爬取跳页url不变的网页表格数据。
url:http://gs.amac.org.cn/amac-infodisc/res/pof/fund/index.html
爬取表格所有页的数据: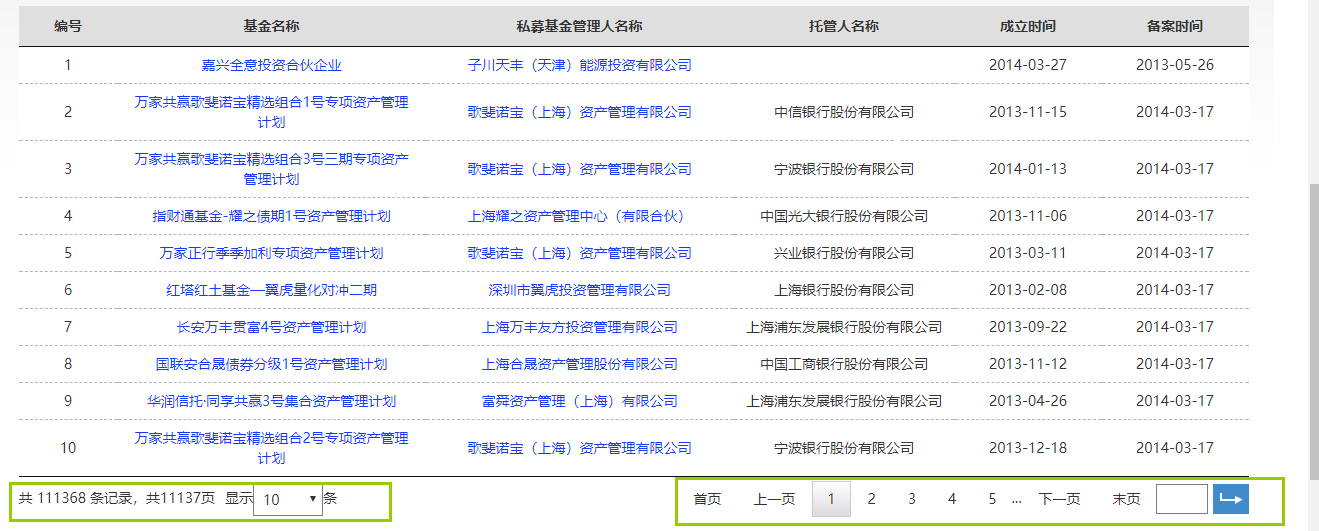
求求大神救救孩纸* _*
数据量不大的话 用selenium 自动化 ,或者抓包分析接口
http://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand=0.7209624051130579&page=2&size=20
确实新手,看得出来
这个网页应该跟异步加载型的网页差不多,或者这也算是是防爬虫的手段吧。
数据是通过另一个接口的请求得到的,而不是直接由html文件给出的。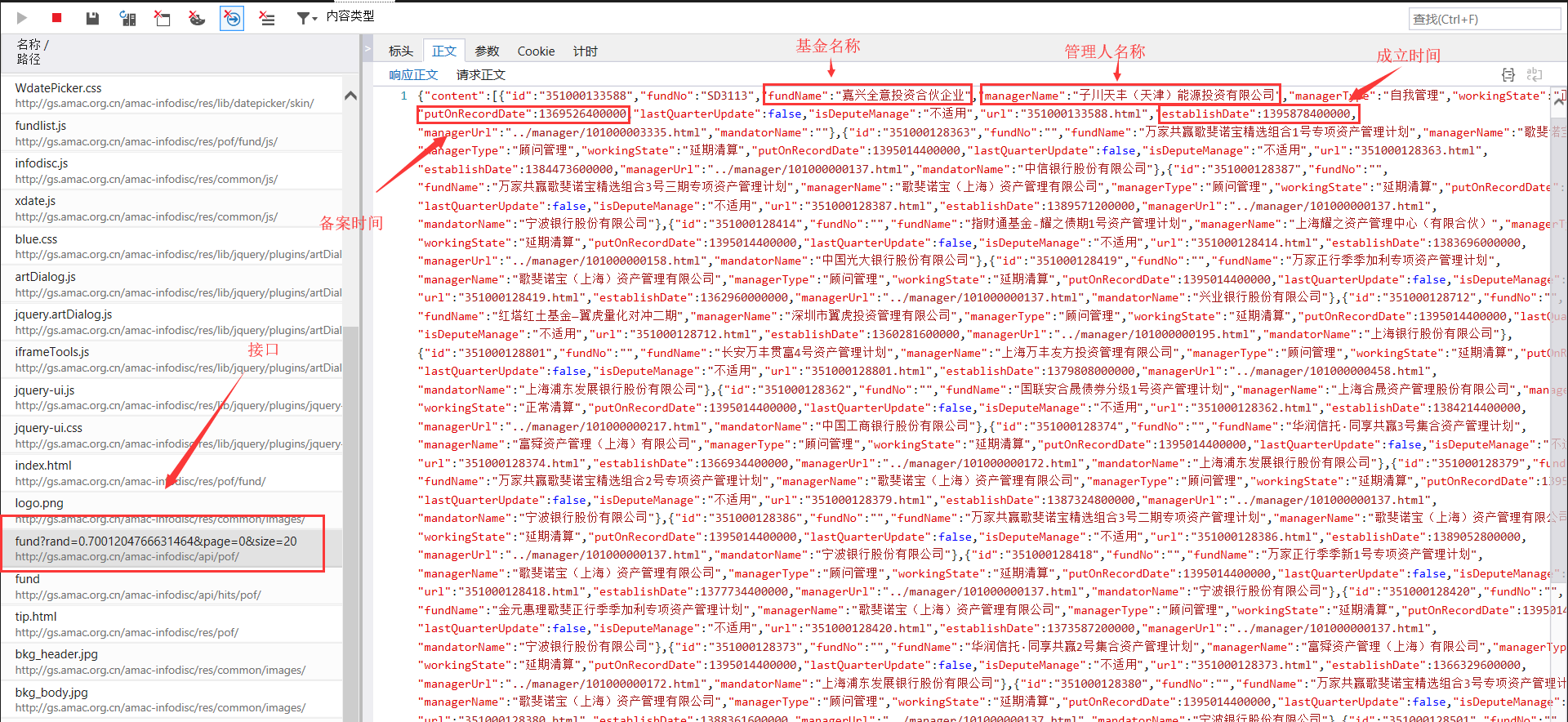
接口中相应参数的变化,应该会使数据的返回不一样。
就给个简短的思路:
(1) 获取接口的数据(headers头部)
(2)提取接口数据 (json模块)
(3)时间戳的转换 (time模块)
(4)等等
应该是这样吧
附上代码:
import requests
import json
import random
import openpyxl
import time
获取每一页的数据
def get_content(page):
url = "http://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand={}&page={}&size=100".format(random.random(), page)
headers = {
'Content-Type': 'application/json',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
data = {}
rsp = requests.post(url=url, headers=headers, data=json.dumps(data)) # 发起请求
json_str = json.loads(rsp.text) # 转为json处理
return json_str
json_str = get_content(0) # 访问第一页
totalPages = json_str['totalPages'] # 获取总页数
创建excel
xls = openpyxl.Workbook()
激活sheet
sheet = xls.active
要保存的列头
title = ['基金名称', '私募基金管理人名称', '托管人名称', '成立时间', '备案时间']
添加列头
sheet.append(title)
for page in range(0, totalPages+1): # 循环遍历获取每一页数据
print("当前第{}页中".format(page+1))
json_str = get_content(page) # 每次访问100条数据
for item in json_str['content']:
if item['establishDate'] == None:
start_time = ''
else :
timeArray = time.localtime(item['establishDate']/1000) # 格式化时间戳
start_time = time.strftime("%Y-%m-%d", timeArray)
if item['putOnRecordDate'] == None:
end_time = ''
else :
timeArray = time.localtime(item['putOnRecordDate']/1000) # 格式化时间戳
end_time = time.strftime("%Y-%m-%d", timeArray)
# 添加到excel中每一行
sheet.append([item['fundName'], item['managerName'], item['mandatorName'], start_time, end_time])
time.sleep(1)
保存
xls.save('zjzj.xlsx')
print("抓取完成")