在写爬虫运用xlwt库将网页信息写入execl中遇到的问题
问题遇到的现象和发生背景
使用xlwt库将爬虫获取当当网的图书信息写入excel中时遇到了数据格式错误无法写入的问题
问题相关代码
import requests
import xlwt
def dangdang(url):
res = requests.get(url, headers=headers)
res.encoding =res.apparent_encoding
book = xlwt.Workbook(encoding='utf-8')
sheet = book.add_sheet('Book')
cont =0
dom = etree.HTML(res.text, etree.HTMLParser())
book_infos = dom.xpath('//li[starts-with(@class, "line")]')
for book_info in book_infos:
date = []
...................................(此处使用了xpath语句对网页内容进行抓取)
date.append(name), date.append(now_price), date.append(pre_price), date.append(author), date.append(time), date.append(publisher), date.append(comment), date.append(detail)
# 遍历输入数据到工作簿里面
for i in range(cont, cont + 1):
for a, b in enumerate(date):# 使用enumerate函数返回列表的索引和对应的值
sheet.write(i,a,b) # 将数据写入到工作簿里面
cont += 1 # 循环结束行数加一
info = {
'书名': name,
'折扣价': now_price,
'定价': pre_price,
'作者': author,
'出版日期': out_date.replace(' /', ''),
'出版社': publisher,
'评论数': comment,
'简介': detail
}
print(info)
book.save('Book.xls')
运行结果及报错内容
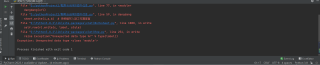
我的解答思路和尝试过的方法
曾在CSDN中搜索知道是数据格式问题,但本人语法功底较差,在使用了几次不同的数据强制类型转换后问题仍未得到解决,故在此求各位指点。
我想要达到的结果

你抓回来的数据比如name,是这样的[name,],不是字符串就是个列表,你把列表再往表格里写,当然写不进去,你爬下来的比如name之类用join都给变成单个字符串,就能写进去了