SQL server2008r2 怎么删除一个表内得重复项
有一个100万得表1,里面整行重复的有12万,第一列重复(其他不重复)的有15万
怎么删掉这12万和15万条只留下唯一得
表1
无id号的情况下,删除数据库的特定行
很明显整行重复的在第一列重复的,删除第一列重复的即可
删除第一列重复
with t1(rownum) as ( select row_number () over(PARTITION BY aa order by aa) from 表1)
delete from t1 where t1.rownum>1
select * from 表1
删除整行重复
with t1(rownum) as ( select row_number () over(PARTITION BY aa,bb,省,市 order by aa) from 表1)
delete from t1 where t1.rownum>1
select * from 表1
如果是删除所有有重复的记录:
delete from 表名 where 编码 in(select 编码 from 表名 group by 编码 having count(1) >= 2)
如果需要留其中一个记录(留下内容最多的一条):
delete from 表名 where 编码 in(select 编码 from 表名 group by 编码 having count(1) >= 2)
and 编码 not in (select max(编码)from 表名 group by 编码 having count(1) >=2)
第一步 表结构新加一列 设计为自增长 假设新加列名为:“ID“
第二步:delete from 表名 where ID in(select max(ID) from 表名 group by 编码 having count(1) >= 2)
第三步:用第二步的思路删其它要删的
最后:删 除新加列ID
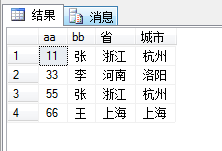
如果你是想要图1的结果,也就是你说的全部删除,就用下面这个sql

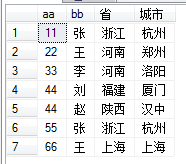
如果你想要的是图2下面这样的数据,用下面这个sql

如果都不是,请说明你要的结果
这个我有处理经验,只是很费时间
先建一个Temp Table ,建好primary key Column (即唯一值不能重复)
再用程序抓数据,转成Insert into SQL
写入Temp Table 时,如有错误则Pass ,继续写入下一笔
如此,保证可取得不重复的资料