中文文本分类数据预处理
我想把公众文章内容就行去除特殊符号,分词,导入停用词表,并去停用词,结果也是以这样表的形式
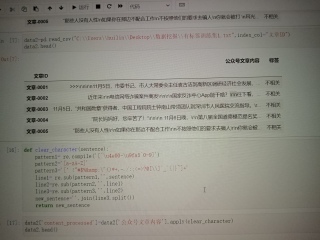
是在juypter上的操作
你的是简单清洗处理,如果要分词,用jieba模块可以满足你需求
直接在dataframe中处理,调用jieba分词函数:
import pandas as pd
import re
import jieba
d=pd.read_excel('0413.xlsx')
stopwords=['月','日','了','啥']
def clean_character(sentence):
p1=re.compile('[^\u4e00-\u9fa5]')
sentence=re.sub(p1,'',sentence)
return sentence
d['预处理后句子']=d['公众号文章内容'].apply(clean_character)
d['分词']=d['预处理后句子'].apply(lambda x:[x for x in jieba.cut(x) if x not in stopwords])
print(d)
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632