pycharm社区版写了一个小的网页打开,但是返回值结果一直为10
问题遇到的现象和发生背景
在pycharm中用urllib.request里的urlopen打开百度的首页时,想要爬取百度首页的内容时,使用print函数无法得到具体的页面信息,所得结果返回值一直保持为10,更换其他页面也一样。但是程序运行并无报错。
问题相关代码
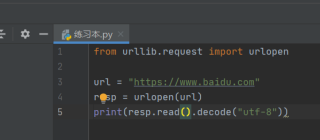
运行结果及报错内容

你的代码我运行了下没问题,是不是一直运行的其他文件?
from urllib.request import urlopen
myURL = urlopen("http://www.baidu.com/")
print(myURL.read().decode('utf-8'))
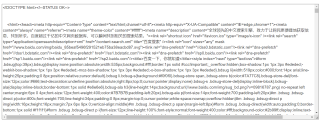
user-agent请求头要加上,示例代码如下

import urllib.request
url='https://www.baidu.com/'
headers=('user-agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36')
opener=urllib.request.build_opener()
opener.addheaders=[headers]
resp=opener.open(url)
print(resp.read().decode('utf-8'))

PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632