xgboost代码运行错误,如何解决?
使用xgboost对pima-indians-diabetes.csv数据进行分类处理时,代码无法运行
问题相关代码
import xgboost# First XGBoost model for Pima Indians dataset
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
load data
dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")
split data into X and y
X = dataset[:,0:8]
Y = dataset[:,8]
split data into train and test sets
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
fit model no training data
model = XGBClassifier()
model.fit(X_train, y_train)
make predictions for test data
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
evaluate predictions
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
运行结果及报错内容
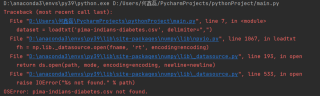
请问问题的原因是什么?该如何解决
查看一下dataset = loadtxt('pima-indians-diabetes.csv', delimiter=",")里的路径,即在当前运行脚本目录下有没有此文件。可写成绝对路径试试。
您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632