MySql 千万级数据量 查询很慢

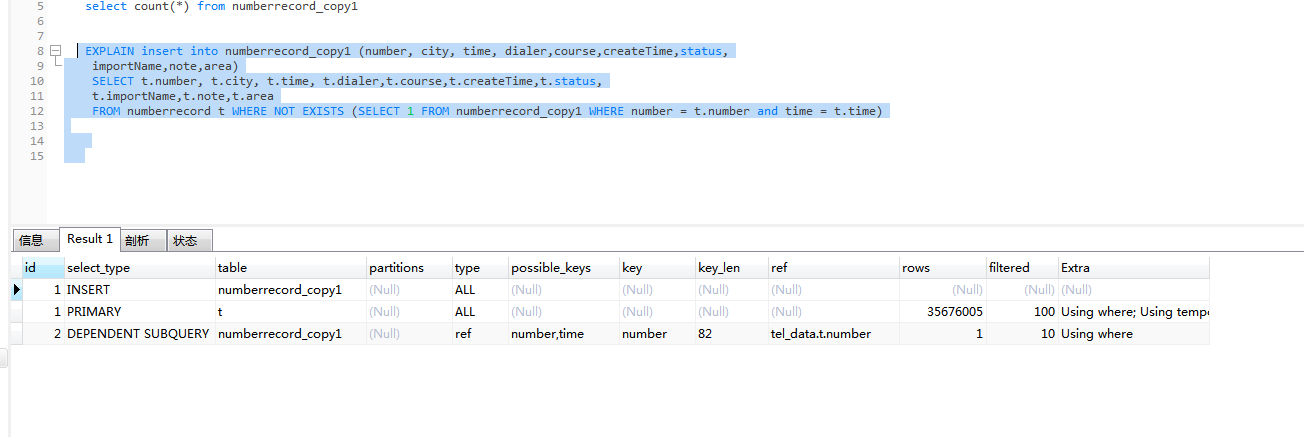
如图:numberrecord 表 3600W数据量。
需求是去重掉 time 与 number一致的数据。 我用的去重插入复制表的方法。
目前已经执行12个小时了,一夜没睡。
试过用java去处理,多线程分页查询去重,jvm直接崩溃。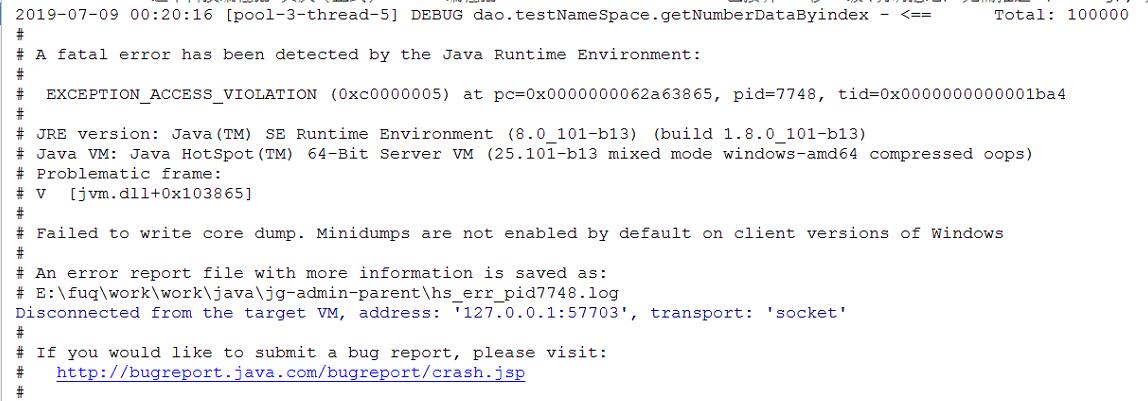
VM options : -Xms5000m -Xmx8000m 电脑内存16G的
问题2就是3600W数据
SELECT number FROM numberrecord where time <'2019-07-08' group by number
需要查询出 2019-07-08之前的所有number数据. 这个sql 如何优化。
time,number都有索引
求大牛给个高效率解决方案。
按月分表完美解决问题
对time列做索引,time列使用timestamp类型存储,千万不要字符串,还不行的话,分库份表查询再union
首先这么复杂和数据量大的操作是一定不能放在SQL中来实现。
应该考虑在代码中分页实现,你在代码中报错只是因为没写好而已。
思路大概是:对应表建好索引。分页十万条查询去重后的数据,循环查询分1万条批量插入。
还有类似记录日志统计的数据,应该考虑放在mongodb上
- 这种去重方案,本身不合理。在sql查询中,所有否定谓语,如not like, not in, not exist都不能应用索引
- 去掉重复,可以考虑采用distinct或者group by实现
- 数据量巨大,考虑按时间分区或分库分表,然后在分组查询和合并
使用时间索引,程序中按天进行查询,where条件必须是指定的天,不能是时间范围
问题2的查询如果加上分页的话就会很快出来,用户不会一次展示上千万条的数据,