【python】csv分类计算求和并输出字典
我有如下的csv,想要进行分类求和
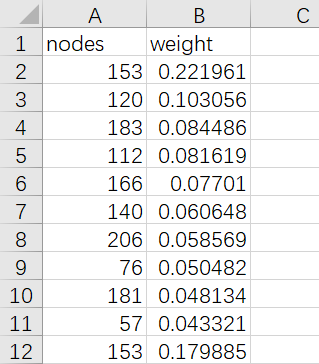
如果第一列数值相同,则第二列的数相加,最后输出一个字典
153 0.221961455
120 0.103056455
183 0.084485641
112 0.08161917
166 0.077010437
140 0.060647912
206 0.058569176
76 0.050482204
181 0.048133912
57 0.04332135
153 0.179884848
举例:如上表输出后153后面数值成为0.401846,最终字典
prDict={153:0.401846,120:0.103056......}
import csv
reader=csv.reader(open('xxxx.csv','r'))
d=dict()
for i in reader:
if reader.line_num==1:
continue
d[int(i[0])]=int(i[1])+d.get(int(i[0]),0)
import pandas as pd
df = df.read_csv('...')
sum_data = df['weight'].groupby(df['nodes']).sum()
大概就是这样一个方法,具体可以看这篇文中的三、2.4部分
【python文本分析】——基于股评文本的情绪分析_貮叁的博客-CSDN博客