(有截图)想问一下关于JAVA Socket编程有关问题,我向豆瓣读书GET请求后,读取响应包,响应头是正常的,但响应体中出现了一些奇奇怪怪的字符串(长度小于4的字符串),跟原网页代码不一样?
JAVA Socket代码如下:
import javax.net.ssl.SSLSocketFactory;
import java.io.*;
import java.net.Socket;
public class Main {
public static void main(String[] args) {
try {
//Https请求用SSLSocketFactory,如果是Http使用Socket
Socket socket = SSLSocketFactory.getDefault().createSocket("140.143.177.206", 443);
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
bw.write("GET /subject/35599714/?icn=index-latestbook-subject HTTP/1.1\r\n");
bw.write("Content-Type: text/html\r\n");
bw.write("Host: book.douban.com\r\n\r\n");
bw.flush();
BufferedReader br = new BufferedReader(new InputStreamReader(socket.getInputStream()));
while(true) {
String readLine = null;
if ((readLine = br.readLine()) != null) {
System.out.println(readLine);
} else {
break;
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行后的结果如下:
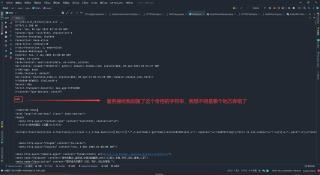
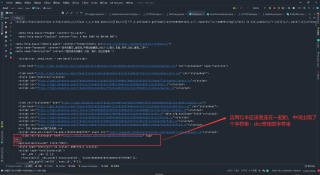
原网站代码如下:可以跟我运行后的结果比较。
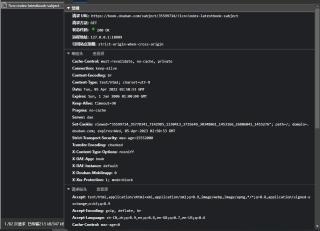
F12 GET请求
查看网页源代码
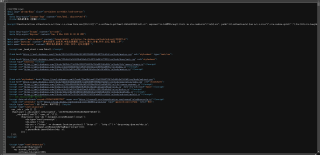
如果用Jsoup爬取的话是没有问题的,所以应该是跟那些地方有关呢?
public class JsoupHTTPS {
public static void main(String[] args) {
Connection connect = Jsoup.connect("https://book.douban.com/subject/35599714/?icn=index-latestbook-subject");
try {
Document document = connect.get();
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
}