python 执行oracle sql 报错 ORA-00900: invalid SQL statement
用python 连接oracle 正常,因为一段sql比较复杂 生成sql 格式文件 然后用python 执行sql 但是报错
sql=r'C:\Temp\frs.sql'
res=cur.execute(sql)
conn.commit()
报错:
res=cur.execute(sql)
DatabaseError: ORA-00900: invalid SQL statement
因为sql里有以下语句 不知是否这个原因
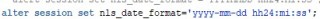
where
date = '20200502'
and datetime='20200502 11:50:00'
怎样解决
来源:https://blog.csdn.net/weixin_39855998/article/details/129014190
# _*_ coding:utf-8 _*_
import os
'''
背景:plsql工具连接oracle数据库不支持批量导入sql脚本,用惯navicat的朋友不太习惯。
操作:
1.第一步登录PLSQL
2.选择File>New>Command Windows(命令窗口)
3.输入@符号,之后敲击回车键。从本地选择执行的SQL脚本。
4.想批量执行sql脚本,可以新建一个文本,使用@拼接本地路径。
5.本脚本执行后,直接执行:@E:\\plsql-python-sql\\finish_sql.txt即可
时间:20230213
'''
class Oraclesql:
def __init__(self, path):
self.path = path
def searchfile(self):
# 检索目标目录文件
list1 = []
file = os.listdir(self.path)
for i in file:
if str(i.split(".")[-1]) == 'sql':
abs = os.path.join(self.path, i)
list1.append("@" + abs + ";")
return list1
def shuchu(self):
# 输出为当前目录下的文件
with open(os.path.join(self.path, "E:\\plsql-python-sql\\finish_sql.txt"), "w+", encoding="utf-8") as file1:
for a in self.searchfile():
file1.write(a + '\n')
if __name__ == "__main__":
# sql脚本存放位置
a = Oraclesql(r"E:\plsql-python-sql")
a.shuchu()
你这运行的是一个文件路径的字符串,当然不行了。至少得先把文件内容读出来吧,当然读出来你也会发现运行不了,因为它一次只能执行一条sql。但一旦你打算分隔语句逐条去执行,又会发现需要sql语法解析器...
所以为啥会有这种场景呢?python是用来写应用代码的,这种sql文件总不会也是python生成的吧?如果只用执行一次,用客户端直接连数据库执行不就好了?如果是做接口需要频繁导入,为啥不直接生成数据文件,然后python读取后再组装sql语句插入呢?
如果你非得用python来启动sql文件的执行,可以通过执行操作系统命令调用oracle客户端里的sqlplus来执行这个sql文件
定期数据不建议使用sql格式文件,sql格式一般是用于部署或者初始化一次性执行。你这个sql格式的目前只能调用操作系统命令通过sqlplus执行了。这不是复杂sql的问题,而是你一个文件里是有多条语句的,而在客户端一次只能执行一个sql语句或者一个plsql块,所以只能在sqlplus里来执行sql文件,sqlplus会按语法解析器自动把语句拆分并逐条执行
看不懂,你这个写的太少了
是用cx_oracle 吗?
cx_oracle 每次只能执行一条sql语句,而且sql 语句不能有;
大概 这样。 看看你的用法有没有在这个规则下。
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632