C++中获得vector中最后一个元素,使用迭代器.end(),和使用size()取得长度,哪个效率更高?
如
vector v;
int l=v.size();
v[l-1];
和
vector v;
auto p=v.end();
p--;
size()取得长度的效率更高
#include <iostream>
#include <vector>
#include<ctime>
using namespace std;
int main()
{
vector <int> vec;
int i = 0;
for (i = 0; i < 100000; ++i)
vec.push_back(i);
clock_t startTime, endTime;
startTime = clock();//计时开始
for(int i = 0; i < 10000; ++i)
int l = vec.size();
endTime = clock();//计时结束
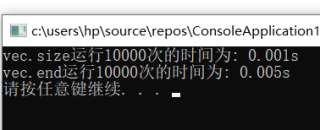
cout << "vec.size运行10000次的时间为: " << (double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl;
startTime = clock();//计时开始
for (int i = 0; i < 10000; ++i)
vector<int> ::iterator p = vec.end();
endTime = clock();//计时结束
cout << "vec.end运行10000次的时间为: " << (double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << endl;
system("pause");
return 0;
}
啊这,纠结这个干啥...你可以自己测试一下,我盲猜第二个快一点
不必纠结这种细微差别。其实这两种写法效率是一样的。下面是GCC编译器加-O3优化选项生成的汇编代码,可以看出两种写法生成的汇编代码完全一样。
#include <cstdio>
#include <vector>
using namespace std;
void f1(const vector<int>& a) { printf("%d\n", a[a.size() - 1]); }
void f2(const vector<int>& a) { printf("%d\n", *--a.end()); }
.LC0:
.string "%d\n"
f1(std::vector<int, std::allocator<int> > const&):
mov rax, QWORD PTR [rdi+8]
mov edi, OFFSET FLAT:.LC0
mov esi, DWORD PTR [rax-4]
xor eax, eax
jmp printf
f2(std::vector<int, std::allocator<int> > const&):
mov rax, QWORD PTR [rdi+8]
mov edi, OFFSET FLAT:.LC0
mov esi, DWORD PTR [rax-4]
xor eax, eax
jmp printf