相同订单号相同商品的订单数量合并,订单行合并(语言-python)
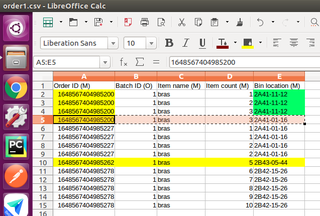
如上图所示订单csv中,第一列为订单号,第四列为数量,第五列为商品货位,相同货位是相同商品.
如果一行中第一列和第五列相同,则将他们第四列的数量相加,变成一行
如果一行中,第一列相同,第五列不同,则不相加,保持原样
处理后生成新的csv变成下图的样子
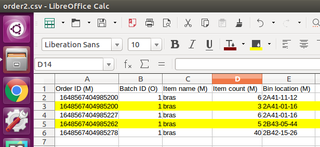
感谢指教和帮忙
Order ID (M),Batch ID (O),Item name (M),Item count (M),Bin location (M)
1648567404985200,1,bras,1,2A41-11-12
1648567404985200,1,bras,2,2A41-11-12
1648567404985200,1,bras,3,2A41-11-12
1648567404985227,1,bras,1,2A41-01-16
1648567404985227,1,bras,1,2A41-01-16
1648567404985227,1,bras,2,2A41-01-16
1648567404985227,1,bras,2,2A41-01-16
1648567404985262,1,bras,5,2B43-05-44
1648567404985278,1,bras,6,2B42-15-26
1648567404985278,1,bras,7,2B42-15-26
1648567404985278,1,bras,8,2B42-15-26
1648567404985278,1,bras,9,2B42-15-26
1648567404985278,1,bras,10,2B42-15-26
先用read_csv 读入数据, 再分组 , 最后to_csv 即可
参考下这个例子
import pandas as pd
list1 = [ ['a001A',1,2,'s001'],['a001A',2,2,'s002'],['c003C',3,3,'s002'],['a001A',4,4,'s001']
,['a001A',3,4,'s001'], ['c003C', 5, 6,'s002'],['c003C',7,8,'s001'] ]
df1 = pd.DataFrame(list1)
df1.columns=['ID','DATA1','DATA2','STOCK']
# 你把以上的代码,换成 read_csv 即可。
print(df1)
df2 = df1[['ID','STOCK','DATA2']].groupby(['ID','STOCK']).sum().reset_index()
print(df2)
df2.to_csv("data_group.csv")
用pandas里面的分组操作即可