大数据 hive 日志解析,数据库设计
只要有帮助都会采纳,从日志部分开始,建议有用的话也会采纳
日志部分:
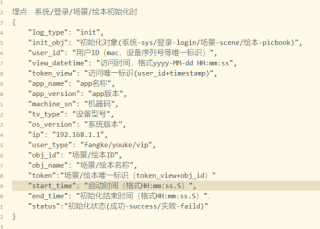


需求:
需求:
1.了解不同地区以及不同用户类型的登录时长情况(信息管理)
筛选条件: 地区、用户ID、电视型号、用户类型

2.不同用户在绘本不同页面的观看时长和次数(用户活跃)
筛选条件: 绘本名称,绘本页码,用户ID

3.了解不同地区、不同用户、不同绘本的访问情况。(用户月报表管理)
筛选条件: 日/周/月 地区:省-市 绘本名称: 用户类型: 时间选择:开始时间,结束时间

4.绘本上架期间,多少用户选择过这个绘本,绘本的稳定性(绘本管理)
筛选条件: 筛选条件:绘本名称,时间选择控件

5.统计pv uv
筛选条件: 绘本名称,绘本页码,用户ID

6.了解不同动作对用户实现和触发的难易程度(动作管理)
筛选条件:日/周/月 地区:省-市 绘本名称: 用户类型: 时间选择:开始时间,结束时间

我的解答思路和尝试过的方法
1.创建json表
create table aicsh(json string);
create table aitchby(json string);
create table aiyhdz(json string);
2,.解析json数据
多层json用 get_json_object
单层json用 json_tuple
目前日志是三个,各自独立,
日志的话我想合成一个多层json
创建对应器字段的大表,(这个要分区吗?按天还是月?)
json解析完成后写入大表
请教下各位,我怎么做,
需要根据不同的需求去创建一个存放结果的表吗?
然后怎样去计算着写指标?
只要有帮助就会采纳感谢,最好从头开始往下弄,从日志开始
有不合理请及时提出
好像还没人回答,帮你热热场。
根据我之前做hadoop的经验,跟你做的这个需求大同小异,我是统计安卓应用商店的各种维度报表。
首先,你说要做合并成一个大的多层json,这个其实没甚必要,颗粒度越细越好,保持3个独立的json日志更好。
其次,大表分区按天,归档按月。
你这6个需求,创建6个表,分别存放结果,对你将来的结构和业务扩展有更大灵活性。
计算指标的过程还是写UDF或者UDTF吧,做成函数,让SQL去调用起来。
算是抛块砖,等玉。
看数据量,
表大的话,建议把关键查询字段建个索引表,然后跟一个纯数据表,表里面就存个索引,后面跟个data,把你的整个json扔进去就行了。用的时候,通过索引表找到数据表中的数据。
表小的话,就都放在一起,按照时间hash,该归档归档,保证表体积在一个健康的范围内。
参考日志的信息、数量以及你的需求来说,个人倾向于你的第一种方案,根据不同的需求建立多个不同的表,不建议存成json大文本的数据格式,一方面数据结构过于复杂,不便于解析;另一方面不利于需求维护,一旦需求所有更改,代码修改量过大,而且限于json的数据结构,比较麻烦
方案思路:
1、信息管理表,主要用于存储需求1的地区、用户ID、电视型号、用户类型等相关字段
2、绘本详情表,将绘本的基础信息,主要用于存储绘本名称,绘本页码等基础信息
3、用户绘本中间表,主要用于管理信息管理和绘本详情表,将关联关系通过该表进行维护,而不是放到业务表中,以免单个绘本对应多个用户信息的情况
4、动作管理表,用于存储需求6对应的一些基本信息字段
一般日志接入,最好要有ods层,即怎么来的就怎么存,不做任何处理,最多加个分区字段,比如按天。这样子有利于后续日志的错误排查或溯源等操作。分开不同表存储比较好,有利于各种需求的查询,没必要合并大表,合并成大表大多数时候都只是为了假如数据量大为了减少join带来的性能损耗。另外不要存储成json字段,按字段分开存,先不论多次查询的性能损耗,单单查询语句看起来就太麻烦了。写成json很多时候除非就是遇到扩展字段不固定这种情况。对于是否要分区,就看你的数据量了,每天数据量才几万或几十万则完全没必要分区,分区过多,表一多起来,后面会给hive带来很大的影响,因为元数据是存储在mysql里的。结果表也是可以分开存放的。