在用xpath定位网页数据的时候怎么通过定位a标签来判断标签下的span标签数据是一个还是两个?
在用xpath定位网页源码数据的时候怎么样才能
通过定位a标签来判断存在span标签下的价格是一个还是两个?
当他为一个的时候直接输出,当他为两个的时候输出字符串 “价格1~价格2”

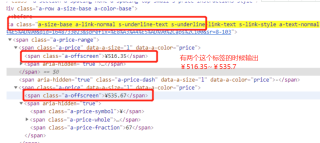
尝试从上层节点进行选取,用text获取全部文本,然后选取拼接。
s = '''<span class="a-price" data-a-size="l" data-a-color="price"><span class="a-offscreen">¥516.35</span><span aria-hidden="true"><span class="a-price-symbol">¥</span><span class="a-price-whole">516<span class="a-price-decimal">.</span></span><span class="a-price-fraction">35</span></span></span>
<span aria-hidden="true" class="a-price-dash" data-a-size="l" data-a-color="price">-</span>
<span class="a-price" data-a-size="l" data-a-color="price"><span class="a-offscreen">¥535.67</span></span><span aria-hidden="true"><span class="a-price-symbol">¥</span><span class="a-price-whole">535<span class="a-price-decimal">.</span></span><span class="a-price-fraction">67</span></span></span>'''
from lxml import etree
html=etree.HTML(s)
sp = html.xpath('//span[@class="a-price"]//text()')
if len(sp)==1:
print(sp[0])
else:
print(sp[0]+'-'+sp[-1])
¥516.35-¥535.67
参考代码如下:
from lxml import etree
text = '''
<a href="" class="xxx">
<span class="ZZZZZZ">
<span class="a-offscreen">¥123</span>
<span class="AAAAAAA"></span>
</span>
<span class="ZZZZZZ">
<span class="a-offscreen">¥145</span>
</span>
</a>
'''
rt = etree.HTML(text)
li = rt.xpath('//a[@class="xxx"]//span[@class="a-offscreen"]')
print(f'有{len(li)}个span class="a-offscreen"')
if len(li)==1:
print(li[0].text)
else:
print(li[0].text+'~'+li[1].text)

您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!如有帮助,请点击我的回答下方的【采纳该答案】按钮帮忙采纳下,谢谢!

PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632