Python,爬虫 HTML代码不理解
请问这几行怎么理解呀,那个a标签怎么只有数字里面,爬虫的时候改怎么去搜索这个位置呀
网页上点击这个2会跳转下一页
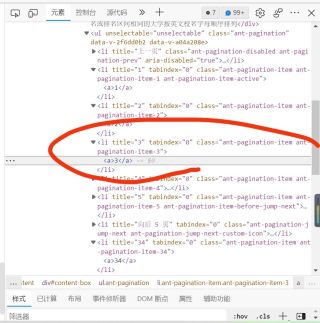
鼠标右击复制xpath路径即可。 那下一页的按钮应该是li节点
//*[@id="content-box"]/ul/li[4]
使用beautifulsoup4
from bs4 import BeautifulSoup as bs
soup = bs(text, 'html.parser') # text是网站的源代码
li = soup.find('li', class_='把标签里的class复制下来')
a = li.find('a') # 这个就是a标签