python requests.get方法在不同环境下结果不同
问题遇到的现象和发生背景
我在我windows的环境下pycharm上写的py脚本,运行没问题,想要放到自己阿里云的服务器centos上运行。但是requests.get得到的结果不同,找了半天找不到原因。
问题相关代码
主要是windows下正常,但是阿里云服务器上结果就不对,具体看截图
import requests
from bs4 import BeautifulSoup
import time
import smtplib
from email.mime.text import MIMEText
from email.header import Header
# 获得最新内容
def getContent():
header = {
'Host': 'jyj.hefei.gov.cn',
'Referer': 'http: // jyj.hefei.gov.cn / index.html',
'Cookie': 'hefei_gove_SHIROJSESSIONID=5abba3f8 - 8c5a - 471c - 844e-97002576eac2',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36'
}
target = 'http://jyj.hefei.gov.cn/jydt/tzgg/index.html'
r = requests.get(url=target, headers=header)
r.encoding = 'utf-8'
html = BeautifulSoup(r.text, 'lxml')
print(html)
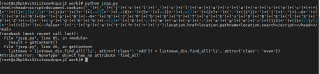
运行结果及报错内容
阿里云服务器上的结果如下,得到的网页压根就不对,弄得我好懵逼
我的解答思路和尝试过的方法
原先我是没有加header的,但是怕是因为没有header的原因就加了,但是还是不对。
我的爬虫是只爬一次的,所以应该也不存在什么被识别出来后限制的。
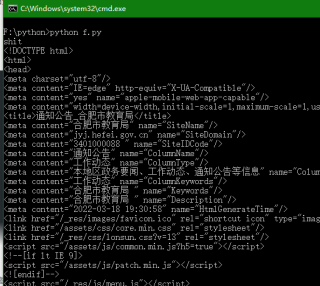
这网站反扒的是__jsluid_h和__jsl_clearance这2个cookie,很怀疑题主自己电脑上能正常运行。。而且这2个cookie是有有效期的,超过一段时间会失效
改下就正常了,如果还是返回截图所示的html代码,说明cookie失效了,题主自己重新通过浏览器获取
import requests
from bs4 import BeautifulSoup
# 获得最新内容
def getContent():
header = {
'Cookie': '__jsluid_h=fb7034571a23a803d104b990f74be267; __jsl_clearance=1647697311.566|0|G%2FamhvTwo65kc9QJ4I1hzPM8RTk%3D;',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
print('shit')
target = 'http://jyj.hefei.gov.cn/jydt/tzgg/index.html'
r = requests.get(target, headers=header)
r.encoding = 'utf-8'
html = BeautifulSoup(r.text, 'lxml')
print(html)
getContent()
