用python实现,找出两张表格中指定列中的差异值,并按照表3的格式输出,输出时以SID列前六位码进行分类输出,自动生成六位码命名的文件夹
问题遇到的现象和发生背景:
两张表格以sid列关联后,逐列进行数据比对,发现不一致的数据按照表格3格式输出,并对表格3的sid列前6位码进行分类输出,自动生成六位码命名的文件夹


问题相关代码,请勿粘贴截图
import pandas as pd
df1=pd.read_excel('test.xlsx', sheet_name='内网平台').set_index('sID')
df1.sort_index()
df2=pd.read_excel('test.xlsx', sheet_name='ihaps').set_index('sID')
df_ihaps = df2.groupby(df2.index)[df2.columns[2:4201]].sum()
df_plat=df1.sort_index()
a=df_plat.columns
b=df_ihaps.columns
c=[i for i in b if not i in a]
ihaps=df_ihaps.drop(c,axis=1)
plat=df_plat
for i in ihaps.columns:
df=pd.concat([plat[i],ihaps[i]],axis=1)
df.columns=['old_'+i,'new_'+i]
df['diff']=df[df.columns[0]]-df[df.columns[1]]
df=df[~(df['diff']==0)]
if len(df)==0:continue
df.to_csv(i+'.csv')
运行结果及报错内容
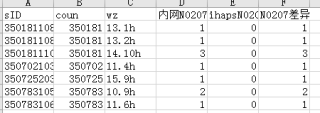
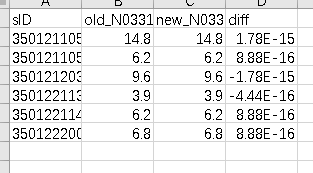
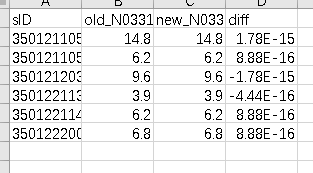
1、输出的表格数据一样,但是相减之后得到一个不为0的值,能否规避这些?(如图)
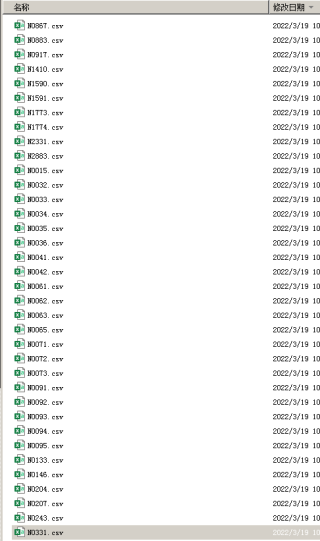
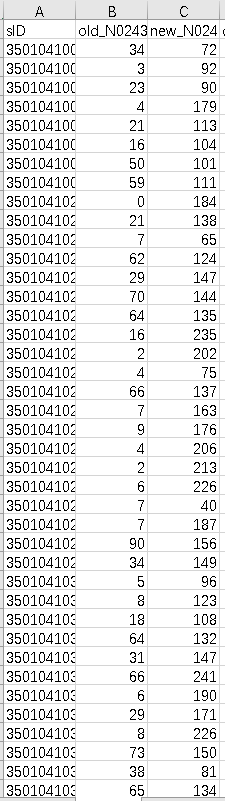
2、代码执行后,输出许多csv文件,能否在输出的时候以sID列分类输出,以df的sID列的前六位数字自动生成文件夹,把这些csv文件分类放入相应的文件夹呢?
我的解答思路和尝试过的方法
我想要达到的结果
1、把结果输出到不同的文件夹中,文件夹名称和表内sid列前六位码一致。

2、解决数据相同,计算结果却不为0的问题,把计算结果为0的都不输出。
谢谢
说个思路
1、数据相同,相减结果不为零,看结果的数据形式,可考虑添加判断,若diff绝对值小于一小值则不输出
df=df[~(abs(df['diff'])<1e-9)]
2、根据6位数字保存至相应文件夹,只需取出该6位数字,判断当前是否存在该文件夹,不存在则新建一个,相应修改保存路径
import os
dirname = i[2:8] # i为循环的文件名
if not os.path.exists(dirname):
os.mkdir(dirname)
...
df.to_csv('dirname\\' + i + '.csv')