留存率的时间区间怎么设置?
取N天 第次、7、30留存
如何设置n的变量,取1月整月 次 7 30留存
select
site `端口`,count(distinct aa.user_id) as`用户数`,
count(distinct bb.user_id) / count(distinct aa.user_id) as`次日留存率`,
count(distinct cc.user_id) / count(distinct aa.user_id) as`7日留存率`,
count(distinct dd.user_id) / count(distinct aa.user_id) as`30日留存率`,aa.dt `日期`
from
( select
distinct dt,
user_id
from 表明
where
dt='N'
) aa
left join (
select
distinct dt,
user_id,
from
表名
where
dt='N+1'
) bb on aa.user_id = bb.user_id
and aa.site = bb.site
left join (
select
distinct dt,
user_id,
from
表名
where
dt='N+7'
) cc on aa.user_id = bb.user_id
and aa.site = cc.site
left join (
select
distinct dt,
user_id,
from
表名
where
dt='N+30'
) dd on aa.user_id = dd.user_id
and aa.site = bb.site
group by
aa.dt,
aa.site
用开窗函数的滑动窗口,可以实现取当前行的下N行,
先提前统计一个数据, dt、site、人数count,3个字段作为子查询,
然后按site分组,按日期排序,取当前行往下数的第7行,比如下面这个,就能在同一行取到第7天的数据了
first_value(人数count) over(partition by site order by dt rows between 7 following and 7 following)
看上去没我之前想的那么简单,还需要排除新用户的影响,那么这个时候就需要先得到一个数据,即每个用户每天在次日、7日、30日时的登录状态,这个可以使用开窗函数中的range between来处理,排序用日期差,这样1天就是一个range
--测试表
create table test_20220318b (dt string,user_id string, site string);
insert into test_20220318b values('20220201','a','app01');
insert into test_20220318b values('20220202','a','app01');
insert into test_20220318b values('20220203','a','app01');
insert into test_20220318b values('20220208','a','app01');
insert into test_20220318b values('20220228','a','app01');
insert into test_20220318b values('20220301','a','app01');
insert into test_20220318b values('20220302','a','app01');
insert into test_20220318b values('20220303','a','app01');
insert into test_20220318b values('20220308','a','app01');
insert into test_20220318b values('20220201','b','app01');
insert into test_20220318b values('20220202','b','app01');
insert into test_20220318b values('20220228','b','app01');
insert into test_20220318b values('20220301','b','app01');
insert into test_20220318b values('20220308','b','app01');
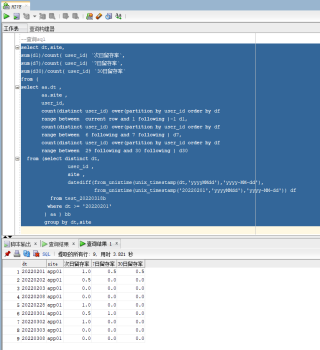
--查询sql
select dt,site,
sum(d1)/count( user_id) `次日留存率`,
sum(d7)/count( user_id) `7日留存率`,
sum(d30)/count( user_id) `30日留存率`
from (
select aa.dt ,
aa.site ,
user_id,
count(distinct user_id) over(partition by user_id order by df
range between current row and 1 following )-1 d1,
count(distinct user_id) over(partition by user_id order by df
range between 6 following and 7 following ) d7,
count(distinct user_id) over(partition by user_id order by df
range between 29 following and 30 following ) d30
from (select distinct dt,
user_id ,
site ,
datediff(from_unixtime(unix_timestamp(dt,'yyyyMMdd'),'yyyy-MM-dd'),
from_unixtime(unix_timestamp('20220201','yyyyMMdd'),'yyyy-MM-dd')) df
from test_20220318b
where dt >= '20220201'
) aa ) bb
group by dt,site