关于爬取图片下载问题
for url in urls:
print(url)
time.sleep(1)
file_name = url.split("/")[-1]
request = urllib.request.Request(url, headers=head)
respons = urllib.request.urlopen(request)
print(type(respons))
with open(file_name,'wb') as f:
f.write(respons.content)
错误提示:
f.write(respons.content)
AttributeError: 'HTTPResponse' object has no attribute 'content'
链接是jpg格式的,怎么修改吖。
去掉content,提示:
f.write(respons)
TypeError: a bytes-like object is required, not 'HTTPResponse'
根据报错,可知,你所爬取的网站并没有成功响应你的请求
你的代码里没有给出url=" ",有可能是你的需要爬取的网址出错了。
jpg格式?如果你需要爬取的内容是图片,那么你需要改一下你的代码了,要以.jpg保存你爬取的图片。
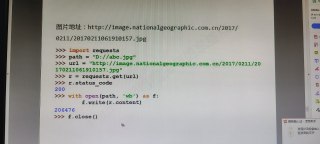
可以看看这图片,如果觉得有帮助,谢谢支持!
以下是我写的代码,以下载百度网页为例,方法供你参考提示
import urllib.request #pyhton3以后urllib2 用urllib.request替代
def download(url):
print('Downloading',url)
try:
html = urllib.request.urlopen(url).read()
except urllib.request.URLError as e:
print('Download error:',e.reason)
html = None
return html
download('http://www.baidu.com')