如何使用pycharm的requests爬取数据,用xpath进行解析的时候为空[?(语言-python)
问题遇到的现象和发生背景
问题相关代码,请勿粘贴截图
job_list = tree.xpath('//div[@class = "j_joblist"]/div/a/p/span/text()')
print(job_list)
运行结果及报错内容


我的解答思路和尝试过的方法
我想要达到的结果
你先输出一下request+s爬取的数据,看看是否有你需要爬取的内容
你检查下这个网页中的内容是不是通过js代码读取外部json数据来动态更新的。
requests只能获取网页的静态源代码,动态更新的内容取不到。
用F12查看到的代码是通过js动态更新后的内容,
要查看网页的静态源代码应该在页面上点击右键,右键菜单中选 "查看网页源代码"。
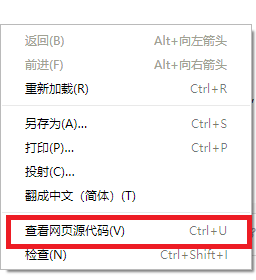
这样看到的才是网页的静态源代码。
如果这个网页的静态源代码中有你需要爬取的内容,就说明该页面没有动态内容,可以用requests爬取。
否则就说明该页面的内容是动态更新的,对于动态更新的内容要用selenium 来爬取。
或者是通过F12控制台分析页面数据加载的链接,找到真正json数据的地址进行爬取。
如果这个网页的静态源代码中有你需要爬取的内容,但requests获取的内容中却没有,可能是requests伪造的头部信息不全。
要在headers中添加抓包时的请求头求参数
比如
url = "https://xxxxxxxxxxx"
headers={
'User-Agent': 'xxxxxxxxxxx',
'Host' : 'xxxxxxxxxxx',
'Origin' : 'xxxxxxxxxxxxx',
'Referer' : 'xxxxxxxxxxxxxx',
'Cookie': 'xxxxxxxxxxxxxxxx'
}
res = requests.get(url,headers=headers)
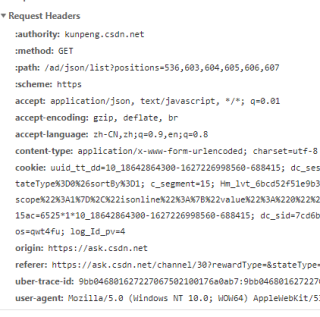
其中请求头的参数 'User-Agent','Host','Origin', 'Referer','Cookie'可以在浏览器的f12控制台的Network中看到
如有帮助,请点击我的回答下方的【采纳该答案】按钮帮忙采纳下,谢谢!

这个网站是异步加载的,请求响应的内容是json格式的数据,
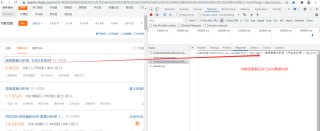
不是html格式的,所以不能用xpath解析,像这种json格式的拿到响应内容,要么用python的字典直接取,要么就用jsonpath取,推荐jsonpath,用法可以看一下我的博客爬虫专栏里的jsonpath相关的那篇文章,我这里简单给你写一下:
import requests
import jsonpath
cookies = {
'_uab_collina': '164727219386374838323863',
'guid': '1198c2e8d8ed093c8d7afbb43a4ec09f',
'adv': 'ad_logid_url%3Dhttps%253A%252F%252Ftrace.51job.com%252Ftrace.php%253Fpartner%253Dsem_pcbaidu5_153527%2526ajp%253DaHR0cHM6Ly9ta3QuNTFqb2IuY29tL3RnL3NlbS9MUF8yMDIwXzEuaHRtbD9mcm9tPWJhaWR1YWQ%253D%2526k%253Dd946ba049bfb67b64f408966cbda3ee9%2526bd_vid%253D10347355564844529671%26%7C%26',
'partner': 'www_baidu_com',
'privacy': '1647272091',
'slife': 'lastvisit%3D010000%26%7C%26',
'acw_tc': '76b20ff116472721861303259e3887dd4d016e0dd2b5967ec5e43ba07b0dcc',
'acw_sc__v2': '622f60fe824234bb2731ed8f2202a6a166030ac4',
'nsearch': 'jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D',
'search': 'jobarea%7E%60010000%7C%21ord_field%7E%600%7C%21recentSearch0%7E%60010000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%CA%FD%BE%DD%B7%D6%CE%F6%CA%A6%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21',
'ssxmod_itna': 'GqmxcD070=LxzxAxeuk4joUYk47ILxX3+hxdD/IGDnqD=GFDK40E5BAxm54mqmxdip0wPqGi=YqfPT+0l+5WYIRMxGLDmKDyliiRqDxrq0rD74irDDxD3Db8dDSDWKD9D0+8BnLuKGWDm+8DGeDeEKODY5DhxDCUmPDwx0Cf1rNfa7FotHm2grhTQh8D7ymDlpxv+G8=+ffYmHhG33QeCxDUnqUTGD4BK+xDmqGAiKDX1QDvayCS6amB99z9xYNNrieNjToN7G3wQG0rGDY8T2ez6iK//0PHjbihjGPkHVeDDaXm7hDD',
'ssxmod_itna2': 'GqmxcD070=LxzxAxeuk4joUYk47ILxX3+hxG9twlQDBdRY47ppomOi+ALFGFQmriFesBmg25iNqdzmOXO4o9k2iOlS6WfXpd1x=Basax/1geOs=tP6ijqj/aB9jh=5KONnAuklUksUY=8BbKnUuL4gLEeMr0R3ehnlOXocuidwRbhik3VAWKovfL=2C3xkmT2Srag0u5a5cW7qkf7EabjUpc8x6T8HjtSIMA4xmys1nUIAq=ouw71HKgvfm6OE/SPpQOvolRqkhMfqpls5vv2o8loIDnCsNYee5uoYG/ZCsCDRxsqXv1DjHwkxnwTPCCUAbELzUL=PT1/LsFLPzk1u3+Fj+puPrQh/ue/qozk+pd4yDmvDDwghPjXqWro2xo6h7CeH4u9PmPiuqQwojqDjKDeqx4D===',
}
headers = {
'Connection': 'keep-alive',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="98", "Google Chrome";v="98"',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua-mobile': '?0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36',
'sec-ch-ua-platform': '"Windows"',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://search.51job.com/list/010000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588,2,2.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
# 第一页和第二页对比,翻页逻辑也清楚了,可以看到翻第n页就在url里n.html就行了
# https://search.51job.com/list/010000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
# https://search.51job.com/list/010000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588,2,2.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
url = 'https://search.51job.com/list/010000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare='
response = requests.get(url, headers=headers, cookies=cookies)
data = response.json()
# print(data)
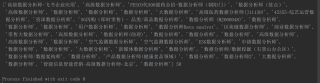
job_names = jsonpath.jsonpath(data,'$..job_name')
print(job_names,len(job_names))
结果:
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632